Social Interaction
Video-Based Studies of Human Sociality
Co-constructing the Video Consultation-competent patient
Ann Merrit Rikke Nielsen
University of Copenhagen
Abstract
Through detailed multimodal EMCA analysis, this paper explores consultations between a geriatric patient in a residential rehabilitation facility, his local caregivers, his relative, and his GP, who is present via telepresence robot. The analysis focuses on a) the patient’s interaction with the telepresence robot and the other participants in the opening sequences, including the establishment of joint attention, as a mutual accomplishment; b) how the role of “the competent Video Consultation (VC)-patient” is negotiated and co-constructed (Goodwin, 2013; Jacoby & Ochs, 1995) over time; and c) how the patient displays increasing VC-competences and develops practices associated with a situational identity as “tech-savvy patient” (Suchman, 2009; Zimmerman, 2008).
Keywords: Video consultation, geriatric patients, co-construction, multimodality, rehabilitation, healthcare, VC-competences, video mediation, telepresence robot, participation framework
Introduction
In recent years, an increasing number of pilot projects have tested the usability of video consultations in public healthcare in Denmark (PAconsulting, 2018). In light of the current pandemic, the need for greater knowledge of how to make video consultations both efficient and beneficial for all involved is paramount. Existing research shows that video-mediated consultations are potentially of enormous benefit to both patients (who could be saved the inconvenience and cost of travel and can benefit from specialist care not locally available), healthcare professionals (who could benefit from collaborations with new colleagues) and the healthcare system (due, in part, to more cost-effective procedures) (Esterle & Mathieu-Fritz, 2013; Geoffroy et al., 2008; Greenhalgh et al., 2016; Lundvoll Nilsen, 2011; Nielsen et al., 2017; Pappas & Seale, 2009; Petersen et al., 2016; Sävenstedt et al., 2004; van den Berg et al., 2012). The use of video consultation also underpins the greater focus in Danish healthcare on increasing self-sufficiency and rehabilitation (PAconsulting, 2018).
Teleconsultation in geriatrics has been examined from the perspective of both professionals (Esterle & Mathieu-Fritz, 2013) and patients (Pappas & Seale, 2009), revealing advantages and challenges. A pilot study by Petersen et al. (2016) pointed to the potential benefits of using video mediation in consultations with older adults. However, very little EMCA-based research has been carried out on teleconsultations with geriatric patients.
This article addresses three closely related aspects of accomplishing mediated multiparty healthcare consultations, namely: a) how the patient’s interaction with the telepresence robot and the other participants, and thereby the meeting itself, is accomplished; b) how the role of “the competent VC-patient” is negotiated and co-constructed over time (Goodwin, 2013; Jacoby & Ochs, 1995); and c) how the patient displays increasing VC-competences and develops practices associated with a situational identity as “tech-savvy patient” (Suchman, 2009; Zimmerman, 2008; Sacks, 1984).
The data for this analysis is taken from four opening sequences of video-mediated healthcare consultations. Doctor-patient interaction is highly institutionalised and is both well-studied and described in a CA context (see e.g. Maynard & Heritage, 2005; Heath 1981). Openings, specifically in face-to-face healthcare encounters, have been extensively studied in CA (Heath, 1981, 1986), showing that in a typical clinical encounter the initial greetings are followed by a question from the healthcare professional regarding the patient’s health, allowing the professional to get “down to business” and establish an agenda (Heath, 1981; Jeffrey David Robinson, 1998; Webb et al., 2013; Have, 1989; Heritage & Maynard, 2006).
Openings in multiparty video-mediated consultations involving one geriatric patient and multiple professionals, similar to those presented here, have been examined using CA by Pappas & Seale (2009). Their study showed that the openings of these teleconsultations involved extensive “floor negotiation” (Sacks et al., 1974), both between the professionals themselves and between professionals and patients, and that the unfamiliarity and complexity of the mediation conducted during consultations required constant negotiation of the skills and roles of all involved partners (Pappas & Seale, 2009).
A distinction between pre-openings, openings, and beginning phases in telehealth is described by Mondada (2015; see also Mlynář et al., 2018). The question of pre-openings (cf. Schegloff, 1979) vs. openings is difficult to address in the data for this study, as the healthcare professionals in each location have typically participated in a video-mediated “pre-meeting” before the patient is introduced to what then becomes the consultation. The meeting then “restarts” or reopens from the perspective of the patient and a new participation framework is negotiated.
There has been a growing interest in longitudinal studies, horizontal change in interactional behaviour over time, and comparability in CA (Pekarek Doehler et al., 2018; Wagner et al., 2018; Doehler, 2010; Melander & Sahlström, 2009; Martin & Sahlström, 2010; Markee, 2008; Lee & Hellermann, 2014; Greer, 2018, 2016; Brouwer & Wagner, 2004; Hall et al., 2011; Hellermann, 2007). This particular study follows the patient over the course of two weeks. During this period, his interactional competences, specifically with regard to the video-mediation, undergoes a number of changes.
Interactional competences (IC) has been defined in different ways in different studies, and with different foci (see, e.g. Pekarek Doehler & Petitjean, 2017; Nguyen, 2012, 2017; Hall et al., 2011). This paper leans primarily on Hall et al.’s definition of IC as “the context-specific constellations of expectations and dispositions about our social worlds that we draw on to navigate our way through our interactions with others” (Hall et al., 2011:1pp), as well as Nguyen’s concept of IC as “the ability to utilize interactional practices contingently in context to achieve actions jointly with other participants in social interaction” (Nguyen, 2017:198). Furthermore, it adopts the concept that IC is co-constructed, and thus any development must be understood as changes not simply within the individual interlocutor, but among the group of participants and their interactions and with regard to the physical setup and surroundings (Nguyen, 2012; Greer, 2018).
The context in which the interaction takes place, including the video mediation and the presence of the telepresence robot, is novel for the patient. The analysis focuses therefore not on all aspects of IC that could be relevant in a doctor-patient encounter, but specifically on IC in relation to the telepresence robot’s mediation of a multiparty consultation. Most co-participants are also relative novices, if not with regard to the video mediation per se, then with regard to the multiparty video-consultation format and the telepresence robot.
2. Data and background
The author, assisted by a student, collected the data for this study in a rural Danish residential rehabilitation facility for geriatric patients, where a pilot-project was being conducted that involved a GP using a remote-controlled telepresence-robot called BEAM (fig. 1) to “visit” patients in the facility. Due to the geographic placement of the facility, no GPs could visit in person, so, in the period before the pilot project was instigated, the affiliated nurse would, if needed, call the individual patients’ GP directly to discuss the patients’ situation and ask for medical advice. The aim of the pilot-project was to test if the use of a telepresence-robot, which allowed a GP to video-consult with the patients and their care personnel, could prevent hospital readmissions while improving the patients’ recovery, and consequently enable a more rapid transfer to the patients’ own home. The data collection formed part of the larger Velux Foundations’ funded project “Professionals’ Use of Video Meetings”.
The first consultation analysed in this article was recorded a day after the patient had arrived at the facility from hospital.

During the consultations, the GP is in his office, some 20 kilometres from the rehabilitation facility. From here, he controls and navigates the BEAM (Fig. 1) using his keyboard. When not in use, the BEAM is docked in a charger and the GP can “wake” it from his office.
Although the BEAM is a machine, its operation is controlled by a human actor and displays that actor’s face on the screen, “speaks” with their voice, moves around the facility, etc. Both patients and staff generally treat the BEAM as a person, addressing it with the GP’s name, for example, or warning against hard-to-see obstacles. Using the BEAM, the GP is virtually present in the room together with the local participants, but simultaneously he has a “body” that moves, establishing a physical presence that enables embodied interaction to a different extent than would be possible if the mediation took place via a stationary computer. The term “Robodoc”, coined by Due (forthcoming), is used in this article when describing the BEAM when it is being controlled by the GP, in situ. For a further discussion of Robodoc as a full member of the interaction, with a “normal” doctor’s epistemic and deontic rights and obligations, see Due (forthcoming).
Two – and sometimes three – cameras were used to record the data. One camera was always mounted next to the GP, filming him in his office as he controlled the BEAM. One camera was permanently mounted on top of the BEAM, allowing the researcher approximately the same view as the GP. In the analysis, what can be observed from this camera is called the “camera zone”, which describes the area one must be in to be visible to the GP. In examples 2 through 4, an additional camera was mounted in the room where the consultation took place, capturing the interaction either from behind or from the side. In the last excerpt, the GP had failed to activate his camera, so only the two cameras at the rehabilitation facility were working.
Synchronised videos from all cameras are inserted at the beginning of each example. The transcripts follow Jefferson’s conventions (Jefferson, 2004) for transcription notation. Furthermore, stills capturing the embodied actions relevant for the analysis have been inserted, inspired by Goodwin (2018, 2013). The recordings from the rehabilitation facility form the basis of the transcripts, and silences and overlaps are transcribed as perceived in that location. The Danish transcript is in black. The English word-by-word transcript is in green. The idiomatic translation is in red. If the word-by-word and idiomatic translations are identical, then the former is omitted.
Even though it can be argued that all interaction is somehow mediated (Arminen et al., 2016), there are some basic preconditions for video-mediated interaction that must be taken into account. From our project, we know that VC-mediated interaction is prone to delay of the audio and visual elements. As a result, pauses in talk are perceived as longer or shorter in one location than in the other, and overlaps might be experienced in one location, but not in the other. Pauses are sometimes very long, due to the parties waiting to see if a current silence is due to the other party having finished a turn – and thus a transition relevant place – or if it is due to delay or other technical issues. Similarly, technical issues can make it difficult to hear people speaking in a low voice or at a certain distance from the microphone. Furthermore, we see that the selection of next speaker is affected. Research shows that in face-to-face interaction, the selection of the next speaker is multimodal and embodied: one can turn towards a person, use one’s gaze, etc. (Deppermann, 2013; Goodwin, 1979, 2000; Mondada, 2007; Rossano et al., 2009; Schegloff, 1985). However, these resources are somewhat lost in the mediation (Raudaskoski, 1999; Pappas & Seale, 2009; Hassert et al, 2016) and the accomplishment of video meetings often, if not always, includes compensating for or taking into account the abovementioned basic conditions.
3. Analysis
The patient is the primary focus of this analysis. It is the mutual accomplishment of his role as “the VC-competent interlocutor” and the co-construction of his local identity as “tech-savvy patient” that is central. “VC-competent interlocutor” is a participant role, which is co-constructed and negotiated in the local participation framework. This paper’s understanding of the participation framework builds on Goffman (Goffman, 1981: 132–132, 137, 226; cf. Levinson, 1988). By taking on their status in a specific speaker (production) or hearer (recipient) role, all participants assume their places in the production format and the participation framework (Goffman, 1981: 132–133, 137; cf. Levinson, 1988: 169; Coupland et al., 2016). When accepting or refusing recipient and/or production roles, such as animator, author, or principal, what is being negotiated are not just local participant roles, but also locally co-constructed situated identities. For the patient to assume the role as “VC-competent interlocutor”, he must both be offered and accept the roles of both ratified, addressed participant and author of relevant utterances (Goffman, 1981: 145, 226; cf. Levinson, 1988) in this specific type of mediated encounter. By doing so he participates in the co-construction of his local situational identity as tech-savvy patient” (Zimmerman, 2008; Suchman, 2009; Sacks, 1984). This article adopts the view that all participant roles and the framework in which they are jointly negotiated are constituted through the participants’ talk, visible embodied actions, and use of space and artifacts, making them ongoing contingent multimodal accomplishments (Goodwin, 1979, 1981, 2000, 2018; Heath, 1986; Levinson, 1988).
The present analysis addresses the following questions: a) how the patient’s interaction with the telepresence robot and the other participants in the opening sequences and the establishment of joint attention necessary for this interaction is mutually accomplished (Kidwell & Zimmerman, 2007; cf. Martin & Sahlström, 2010); b) how the role of “the competent Video Consultation (VC)-patient” is negotiated and co-constructed (Goodwin, 2013; Jacoby & Ochs, 1995); and c) how the patient displays increasing VC-competences and thus over time develops practices associated with a situational identity as “tech-savvy patient” (Suchman, 2009; Sacks, 1984).
The patient (Eric) in the data has been hospitalised for an extended period of time prior to being admitted to the rehabilitation facility, and an untreated Parkinsonism results in him suffering from a number of symptoms, including problems swallowing, poor muscle control, and a very soft tone of voice. The GP (Martin) in the video is the patient’s own, and has been for decades. In the transcript, the abbreviation GP is used to identify the doctor’s utterances, even though they are heard by the interlocutors via the BEAM. In the analysis, GP is used when referring to the doctor’s talk and embodied actions, which can be seen on the screen of the BEAM, whereas the term Robodoc is used when referring to the BEAM as a physical entity present in the room while it is controlled by the GP.
As we join example 1, caregiver Harriet has just had a conversation with the GP about Eric and his situation prior to them entering Eric’s room for the consultation. For a plan of the room and the route the BEAM takes, see Fig. 2. The video contains the example in its entirety, but for the sake of readability, the transcript and analysis of this first long example is divided into three consecutive excerpts (1.1–1.3) below.
Participants are:
Caregiver 1 = CG1 (Harriet)
Caregiver 2 = CG2 (Marge)
General Practitioner = GP (Martin)
Patient = PAT (Eric)
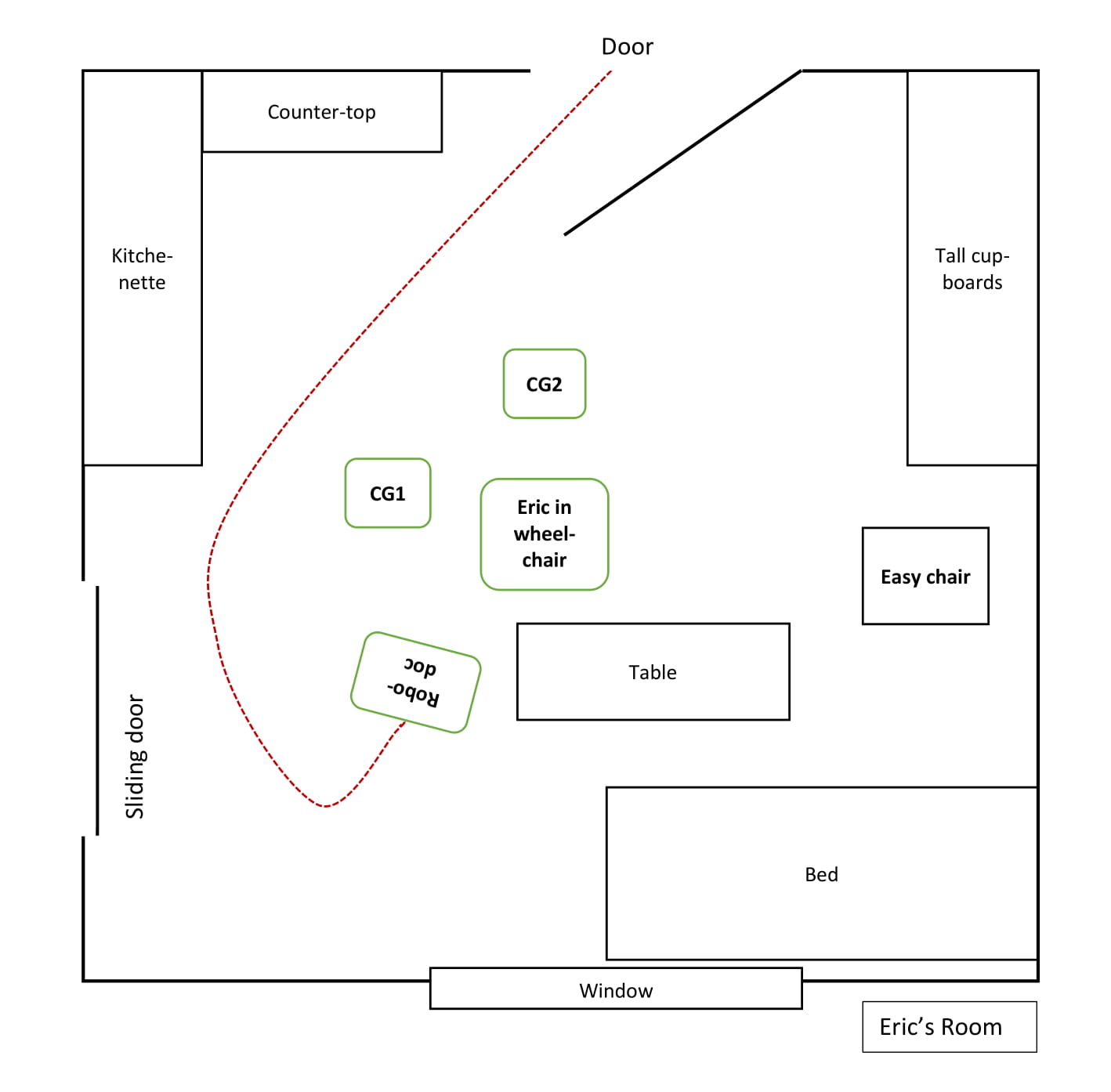
While Robodoc is driving and turning to face Eric, in what Due has termed a face-to-screenface formation (Due, forth), CG1 summons Eric (line 1), who replies with a “yes” (line 3), turns his head and looks at her as she positions herself next to him. She then explicitly draws Eric’s attention to Robodoc, beginning her turn with an imperative (“look”, line 3), before she asks whether Eric remembers their prior talk about Martin visiting (lines 4+5). During her turn, CG1 is bending slightly forwards, thereby physically aligning herself with Eric and sharing his perspective as he turns his head and they both look at Robodoc, accomplishing joint attention, and she stays this way throughout GP’s greeting in line 7 (Fig #1). It is evident from CG1’s stressed “there” (line 5) that their prior conversation has included talking about Eric not being visited in person by GP, but via BEAM. After Eric’s confirming “yes” (line 6), CG1 looks at him briefly and smiles before looking back at the Robodoc, who has come to a stop directly after Eric’s reply.
Once the GP has stopped the Robodoc screenface-to-face with Eric, he greets him with “good morning Eric”, then self-repairs (Schegloff et al., 1977) to “good day” (line 7), as it is past noon. With CG1 standing next to Eric, GP’s recipient designed greeting frames Eric as a ratified, addressed participant in the consultation (Goffman, 1981; Levinson, 1988). Recycling GP’s latter greeting “good day” (line 8), Eric produces a preferred response. However, it is done in a very low voice, which is not hearable in GP’s location.
Having not heard Eric’s greeting, GP begins a new turn by asking for confirmation that Eric can see him (line 9). In overlap, CG1 turns (Fig #2) to ask Eric for confirmation that he recognises GP (“can you see it’s Martin”, line 10), even though Eric has both verbally confirmed that he remembers their talk and has responded to Martin’s greeting. This is a type of repeated use of request for confirmation (RUR) upon answers to close-ended questions, which is often found in atypical interaction involving persons with communicative and cognitive impairments (PWCI) and their caregivers or family members (Rasmussen, 2016; Jeffrey D. Robinson & Heritage, 2005). CG1 asks this while bending forward, turning around and looking at Eric. This position enables her to monitor his response, while not blocking his view of the Robodoc’s screen. Eric confirms with a “yes”, which CG1 recycles with upwards intonation (line 12) while turning further to look at CG2, who has quietly entered the room through the door behind Eric.
After a 2.8-second silence, CG1 takes the floor as she physically steps forward, leans towards Robodoc until she is quite close, and then requests that he turn up the sound a bit (line 14). CG1’s embodied selection of Robodoc as recipient of the turn and her downwards gaze gives the turn a regisseur character (Fig #3), marking this as a sequence “outside the consultation”. Interestingly, CG1 has neither displayed nor addressed that she has trouble hearing GP at any point. Her request to GP thus appears to be meant to ease and underpin Eric’s interaction with Robodoc, ensuring that he can hear GP properly.
After ending her request, she looks at the screen, and holds the gaze for the length of GP’s answer (line 16). After a positive assessment (line 17), CG1 looks away from Robodoc, steps aside, towards the edge of the “camera zone”, then looks at CG2, who is preparing to take a seat behind Eric, and then at Eric, thereby bodily giving the floor back to him. As CG2 remains silent and behind Eric, CG1 and CG2 have now physically co-constructed Eric as primary participant face-to-screenface with Robodoc.
However, in his next turn, GP addresses all three participants using the Danish pronoun “I”, which is a plural “you”, when asking for confirmation that he can be heard (line 18). CG1 and CG2 both verbally confirm this (lines 19 and 20), whereas Eric does not reply verbally but looks at the screen at the exact time that CG1 confirms.
In the silence following the confirmations (line 21), CG1 completely bodily removes herself from the camera zone (Fig #4), essentially making herself invisible for GP, thus reframing her participation status. As she positions herself out of sight of GP, she bodily displays that she does not expect, nor desire to be the addressed recipient of his next utterance, thereby doing a participation role as temporarily unratified participant. Having CG2 behind him, Eric is now bodily and spatially positioned as the ratified and immediately addressable participant (Goffman, 1981:p.133) with full visible and audible access to GP and vice versa.
GP restarts the consultation by greeting Eric using his name (line 22). Eric once again mirrors the greeting (“good day Martin” in line 22). After a 2.5-second silence (line 23), GP addresses Eric with a declarative: “you have been in the hospital” (line 24), which Eric confirms and elaborates upon, while looking down and stating that he has “been through a lot” (line 26).
During the 3.5 seconds of silence following Eric’s reply, CG1 once again steps into the camera zone (#5) while watching Eric. She leans towards the Robodoc and then, looking down, repeats Eric’s answer (lines 28 #6 and 29), much in the same regisseur-like way as in line 12. This time, however, she takes on the participant role of animator or “sounding box” for the utterance of which Eric is author, likely compensating for his low voice, and assuming, due to the prolonged silence, that GP has not heard Eric’s response. CG1 looks back at Eric before looking up at the screen, thus also bodily signaling that this was not “her turn”. In line 31, GP recycles the same phrase, adding a “yes” in downwards intonation at the end of his turn. CG1 confirms, while still looking at Eric, thereby keeping him in the conversation.
In this first example, a lot of work is done to ensure that Eric has both visual and audible access to GP and to co-construct him as ratified participant and author of the last turn. Eric appears as a competent interactant who utilises “interactional practices contingently in context to achieve actions jointly with other participants”, by greeting, confirming recognition, and answering relevantly.
This is the second video meeting in which Eric participates. The overall agenda for the meeting is that the GP will speak to Eric’s wife Lisa, leaving Eric as a ratified but unaddressed participant for most of the meeting. The example below is from the opening sequence and is split into two consecutive excerpts. There are a number of things happening in the room at the beginning of this consultation. As Robodoc enters Eric’s room, several people are following him, one of whom is a student who is there to mount an additional camera on a shelf, and there are no less than four people in Eric’s location who are participants in the consultation, either ratified or unratified. Prior to the first excerpt, GP has greeted Lisa, talking to her briefly, while Eric has been focusing on the student mounting the camera and the other people going in and out of the room.
Participants are:
Caregiver 1 = CG1 (Marge)
Caregiver 2 = CG2 (Jean)
Doctor = GP (Martin)
Patient = PAT (Eric)
Wife = WIF (Lisa)
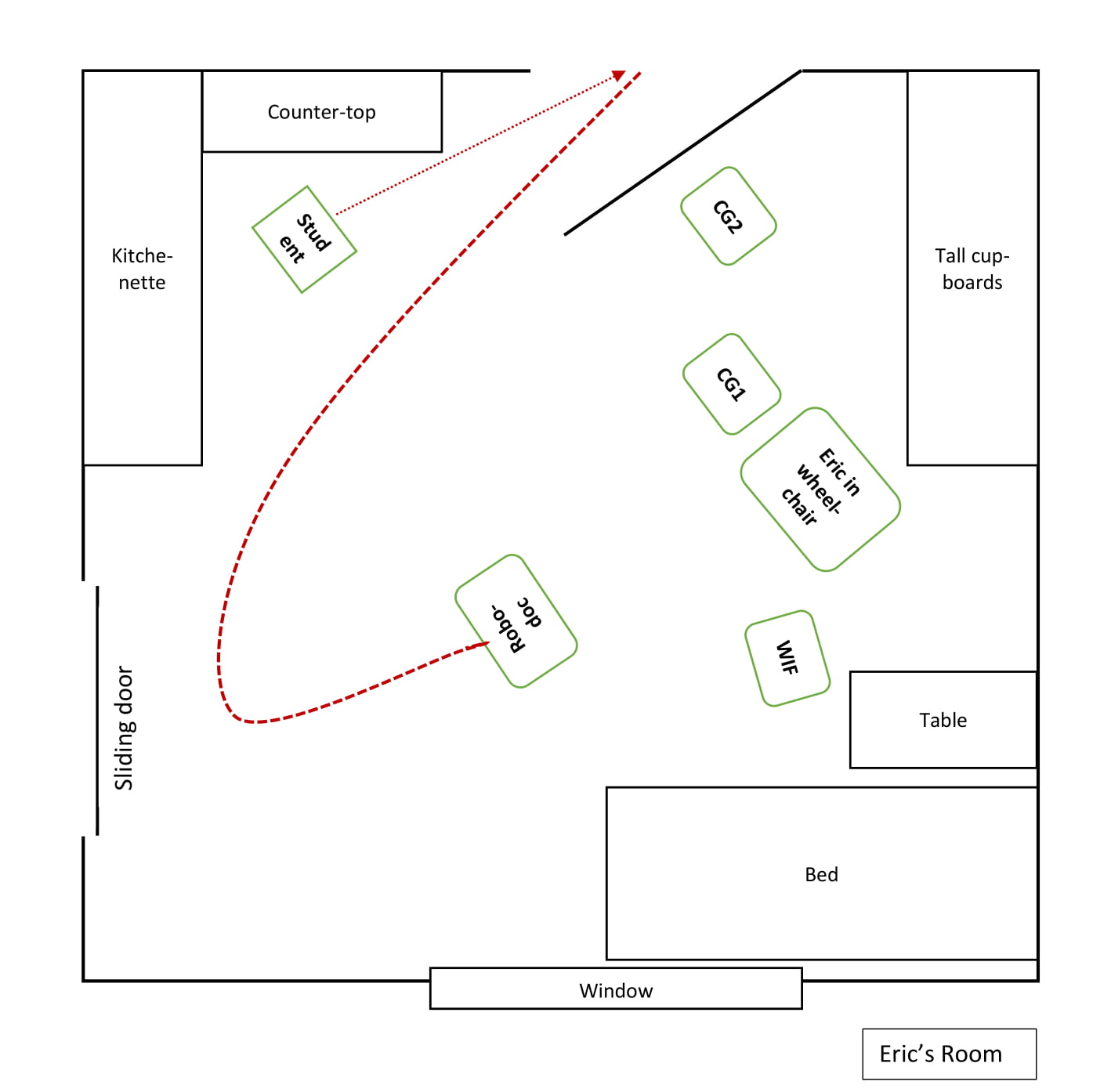
In overlap with WIF finishing her turn (not in transcript), GP greets Eric using his name. Eric responds neither bodily nor verbally, but continues looking in the direction of the student mounting the camera, consequently failing to accept the offered role as ratified hearer and recipient. 0.4 seconds into the silence (line 6), both CG1 and WIF turn to look at him: WIF is patting Eric’s shoulder and CG1 is leaning in, resting her hand on Eric’s wrist (Fig #1) and saying his name (line 7) while looking alternately between Eric and Robodoc, thus trying to direct Eric’s attention to the Robodoc (cf. Martin & Sahlström, 2010; Kidwell & Zimmerman, 2007). During GP’s next turn, in which he requests confirmation that Eric can see him (line 8), Eric orients bodily towards Robodoc, turning his head and looking directly at the screen. However, Eric neither verbally nor gesturally returns the greeting, nor confirms GP’s request for confirmation of visual access. GP then gesturally resumes his turn by waving his hand in front of his face (Fig #2). This happens in overlap with CG1 briefly pointing towards Robodoc while verbally requesting confirmation that Eric has seen GP (line 10), even though Eric is already looking at the screen. Eric holds his gaze, in silence, for almost an additional second, which leads to WIF glossing Martin’s initial greeting “Martin said hi to you” (line 12) while pointing at the screen. At that, Eric looks away from both the screen and her. After a short pause, WIF taps Eric’s knee and, using an imperative (look Eric) while pointing at the screen and briefly looking at it (Fig #3), she once again requests confirmation that Eric has seen GP. As WIF points, Eric turns his head, looks at the screen again and holds his gaze while GP delivers yet another request for confirmation that Eric is aware of his presence (line 14).
It is clear from the extensive use of RUR in these excerpts that the Eric’s “looking at the screen” does not function as sufficient confirmation that he can see and hear GP. In order to be constructed as “VC-competent”, Eric must provide a visible or hearable confirmation of visual access if he is to partake in the establishment of joint attention and contribute sufficiently to the ongoing framework (Goodwin, 2007).
During a silence of more than 4 seconds (line 15), GP utilises the ability that Robodoc affords him to independently move in the remote location, thus actively contributing to the formation of the physical framework and common interactional space. He steers Robodoc closer to Eric. While Robodoc is moving forward, WIF again requests confirmation that Eric can see GP (line 16). In response, Eric turns his head towards WIF (Fig #4) and, in an irritated voice, utters “yes I surely can” (line 17), indicating that he is annoyed specifically with her RURs. WIF responds with “yes” followed by an agreeing sound from CG1 (line 19). WIF then continues her turn, explaining to Eric that GP “has just said hi” to him (line 20). Eric’s embodied response to this consists of straightening up and keeping his gaze on WIF.
After 1.9 seconds of silence, GP makes another request for confirmation that Eric has seen him. This is achieved by first explaining where he is (inside the screen, line 22), at which all participants at the other location look at the screen. After an in-breath, GP continues his turn (line 23) and moves his finger back and forth in front of his own face, much like one does when testing someone’s vision. As Eric does not respond to this, GP continues his turn, first with a declarative “there I am”, then with a question to Eric, “can you hear me”, during which he gestures, moving his hand from his mouth towards the camera. At this, Eric responds with a confirming “yes”. GP’s response, “good”, shows that Eric’s verbal confirmation was the sufficient response in this situation, allowing the conversation to continue with Eric as ratified participant.
This example shows how a large number of both ratified and unratified, addressed and unaddressed participants, paired with disturbances in the local physical surroundings make the accomplishment of the consultation difficult: By being distracted by the student and not being an addressed participant from the onset of the consultation, Eric does not register when GP addresses him with a greeting. He therefore does not initially accept the role as addressed participant. This leads to a pursuit of confirmation from the co-participants in both locations, in the form of RURs, which indicates that Eric’s coparticipants assume that Eric possibly cannot see and understand in the same manner as them, and that he therefore does not have the same sensory and/or cognitive capabilities, although he visually orients directly towards the screen. This makes him visibly frustrated, but it also delineates what is expected from a “VC-competent” participant meaningfully interacting in a VC-consultation, namely an understanding of what functions as a sufficient confirmation that he can see and hear the interlocutor in the other location: clear verbal confirmation.
In this third video consultation, Eric is in his room, where he has been eating with his wife and a caregiver. Robodoc has been driving in and around them and now stands with its “back” to the window and the screenface towards them. Eric is turned away, finishing his meal. CG explains to Eric that “Martin is just behind you”, before turning Eric’s wheelchair so that he is face-to-screenface with Robodoc. Meanwhile GP apologises to everyone for being late. The excerpt begins immediately after WIF’s and CG’s verbal acceptance of the apology.
Participants are:
Caregiver = CG (Marianne)
Doctor = GP (Martin)
Patient = PAT (Eric)
Wife = WIF (Lisa)
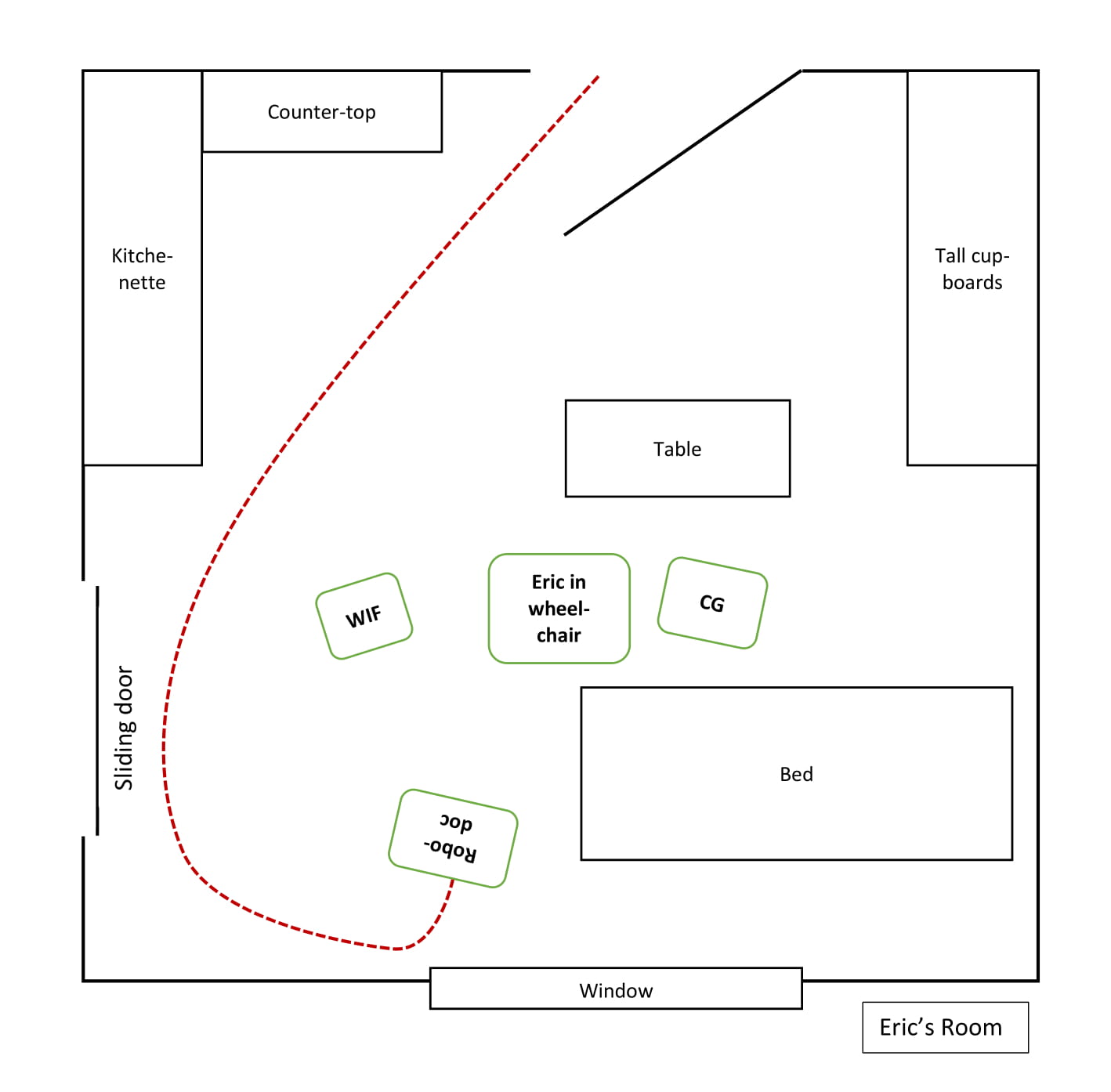
As GP greets Eric, Eric looks from side to side. This immediately elicits embodied reactions from both WIF and CG, who leans towards him and touches him. As CG taps Eric’s shoulder, she self-selects (Fig #1) as next speaker. While pointing at the screen, CG asks Eric whether he can “see Martin is up there” as Eric looks at the screen (Fig #2). After a micro pause, CG resumes her turn, elaborating that GP is “in the TV”, using this old-fashioned term to refer to Robodoc’s screen (line 4). Eric confirms in overlap and in a very low voice (line 5). After a micro-pause, Eric confirms again, in a louder voice, while still looking at the screen (line 7). GP then asks if Eric can hear him, which Eric confirms after a 0.8-second pause with “that too”. This indicates that Eric is now aware, based on the numerous RURs in the prior consultations, of what is considered a sufficient response in a video-meditated context: a turn where he verbally confirms that he can see and hear GP.
Both WIF and CG smile, but GP does not respond, as Eric’s confirmation is not hearable in his location. After a pause of almost 2 seconds, CG self-selects, assuming the animator role as she repeats Eric’s confirmation (line 12), with WIF repeating it immediately after (line 13), thus accomplishing Eric’s turn being heard by GP while he retains his author role in the participation framework. At that, GP smiles (Fig #4) and repeats it as well (line 15), before elaborating by verbalising Eric’s prior confirmation that he can also see GP.
This example serves to illustrate a number of things. Firstly, that all the participants actively partake in the co-construction of Eric as VC-competent participant, who is able to “utilize interactional practices contingently in context to achieve actions jointly with other participants in social interaction” (Nguyen, 2017:198). In this particular context, this means relevantly and sufficiently responding and confirming visibility and audibility, so that the consultation can progress. It also shows that Eric, having been a participant in two prior VC-consultations, now displays knowledge of what is expected of him and how to accept the relevant participant roles that he is offered. This makes it possible for him to display the relevant IC, which contributes to the co-construction of his identity as “tech-savvy patient”. Furthermore, the calmer physical environment, with fewer participants than in Example 2, seems to contribute to Eric’s successful participation.
This last example is very short, and the physical framework is different than in the other three examples. Here, Robodoc is already in Eric’s room when Eric arrives back from lunch. A caregiver is pushing Eric’s wheelchair into his room and directly towards Robodoc. The excerpt begins when the two of them enter the room.
Participants are:
Caregiver = CG (Marianne)
Doctor = GP (Martin)
Patient = PAT (Eric)
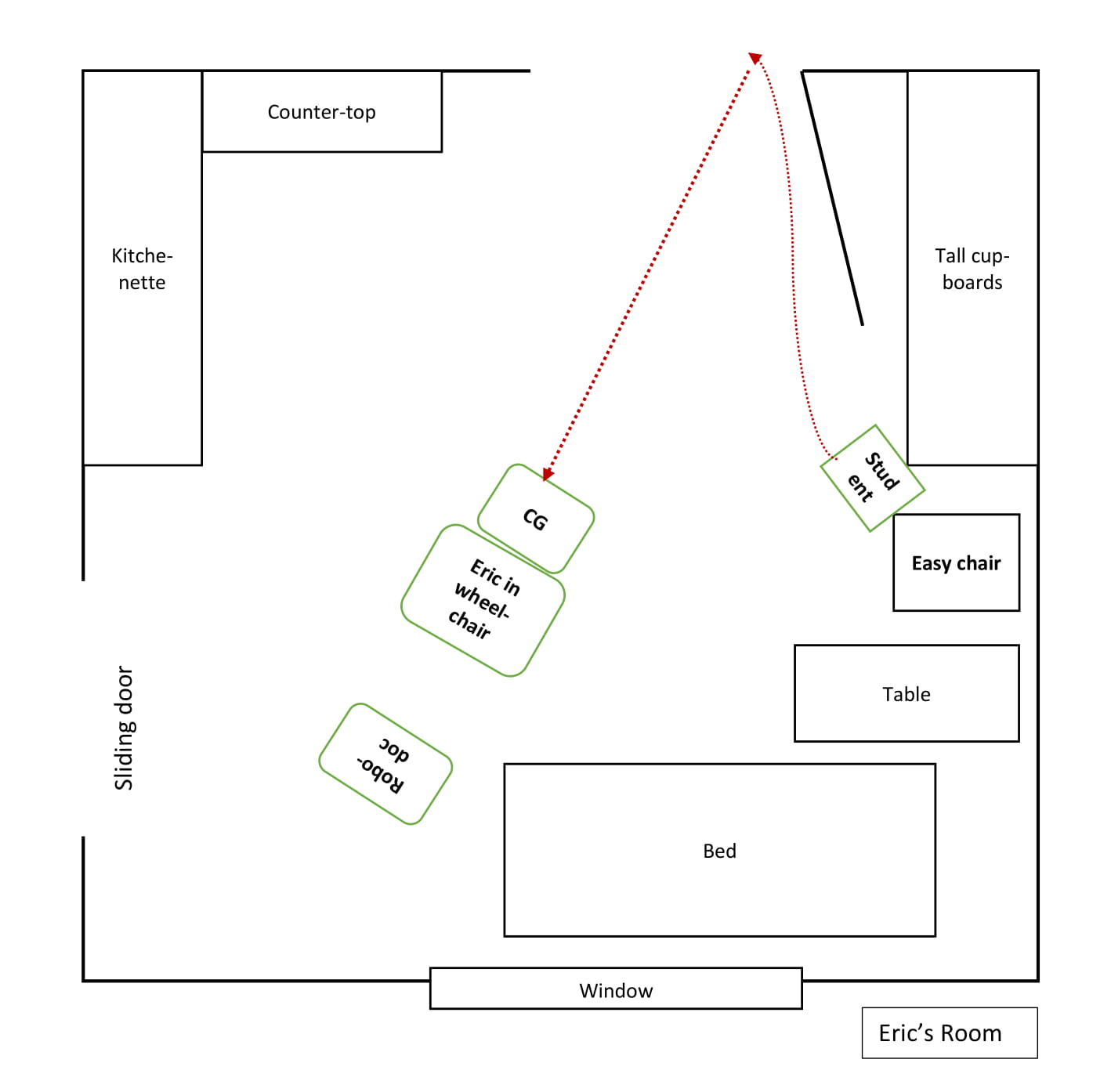
CG is pushing Eric towards the Robodoc while informing him that GP is in the room (line 1). As Eric and CG approach Robodoc, Eric takes the floor with an embodied turn as he looks directly at Robodoc, lifts his hand and nods in greeting while smiling at the screen (Fig #1). This elicits laughter from CG and a reply from GP, who verbally returns his greeting (line 5) and smiles (Fig #2). After 1.8 seconds, GP resumes his turn by stating his observation that Eric’s embodied greeting shows that he now knows what is expected and is sufficient. The calm and simple physical set-up – in which Eric is first verbally prepared by CG that GP is in the room, and Eric then gets immediate visual access to GP, with only minor disturbances and no ratified co-participants – clearly makes it easier for Eric to interact with GP. In this excerpt, Eric displays both knowledge of what is expected and the competence to act on it. Eric is actively participating in the co-construction of himself as VC-competent patient, who by now knows that not just verbal but also gestural displays of confirmation of visibility and audibility are both sufficient and useful for establishing the joint attention necessary to continue the consultation. He is thus with increasing effortlessness partaking in practices associated with the situational identity as “tech-savvy patient”.
4. Concluding discussion
The analyses of these four examples illustrate how all the participants strive to co-create Eric as ratified and addressed participant, thereby accomplishing the openings of the video-mediated consultations between Eric and his GP. Although some of Eric’s co-participants’ interactional contributions, such as the RURs, can appear more annoying than helpful to Eric, they are simultaneously part of the “context-specific constellations of expectations and dispositions about our social worlds” (Hall et al., 2011) that Eric draws when developing his CI.
It is clear from the analyses that the physical setup has an impact on Eric’s ability to focus on and partake in the consultation, and thus accomplish it. The more complex and disturbing Eric’s local environment, the harder it becomes for him to navigate the mediated setting, as he gets distracted by all that is happening around him. Furthermore, it also makes it difficult for Eric’s co-participants to register his embodied contributions to the interaction. Taking into account that Eric’s Parkinsonism is currently untreated, it seems likely that some of his frustrated or annoyed reactions are a consequence of his embodied responses not being acknowledged, but rather being met with RURs.
As can be seen from the analyses, Eric displays increasing VC-competences over the course of the two weeks. To a greater and greater degree, he utilises “interactional practices contingently in context to achieve actions jointly with other participants in social interaction” (Nguyen, 2017:198) when he interactionally displays his knowledge of what is considered an adequate context-specific reaction to the Robodoc, thus doing the situated identity “tech-savvy patient”.
This study shows that video-mediated consultations with an elderly citizen with multiple diagnoses, one of which affects both his tone of voice, and with no prior experience with video-mediation can be successful. In Eric’s case, preparation and a calm environment, in which only relevant participants are present, combined with keen attention to both Eric’s verbal and embodied interactional contributions from all his co-participants seem paramount for a smooth and successful accomplishment of the consultation. The attractive identity that Eric co-creates in the mediated consultations opens a space where he can actively display both agency and competences. This is something that elderly citizens who have one or more diagnoses, which negatively impact their self-reliance have limited options to display in institutional settings. Thus, the VC format proves to be an advantage for Eric himself, beyond the obvious fact that he is receiving proper healthcare.
One aspect not dealt with in the analysis, but which is likely to be a contributing factor to the relative success of the four consultations, is the fact that Eric and the GP, Martin, have known each other for many years. This ensures that although the setting is new for Eric, the key-interlocutor is not. Interviews conducted with staff, patients and relatives during the study show that all have found the VC format very useful, but even more so when the GP was the patients’ own, as this provides increased familiarity and comfort for both patients and their relatives. Nevertheless, even when the GP was unknown to the patient, they generally welcomed the Robodoc consultations.
Acknowledgements
Thanks to the reviewers for helpful feedback. Thanks to my colleagues in the Velux Foundations’ project “Professionals’ Use of Video Meetings” for feedback on the data and my analyses. Thanks to the Velux Foundations for funding the project.
References
Arminen, I., Licoppe, C., & Spagnolli, A. (2016). Respecifying Mediated Interaction. Research on Language and Social Interaction, 49(4), 290–309. https://doi.org/10.1080/08351813.2016.1234614
Brouwer, C. E., & Wagner, J. (2004). Developmental issues in second language conversation. Journal of Applied Linguistics, 1(1), 29–47. https://doi.org/10.1558/japl.1.1.29.55873
Deppermann, A. (2013). Turn-design at turn-beginnings: Multimodal resources to deal with tasks of turn-construction in German. Journal of Pragmatics, 46(1), 91–121. https://doi.org/10.1016/j.pragma.2012.07.010
Doehler, S. P. (2010). Conceptual Changes and Methodological Challenges: On Language and Learning from a Conversation Analytic Perspective on SLA. In P. Seedhouse, S. Walsh, & C. Jenks (Eds.), Conceptualising ‘Learning’ in Applied Linguistics (pp. 105–126). London: Palgrave Macmillan. https://doi.org/10.1057/9780230289772_7
Due, B. (forth). RoboDoc: Semiotic resources for achieving face-to-screenface formation with a telepresence robot. Semiotica.
Esterle, L., & Mathieu-Fritz, A. (2013). Teleconsultation in geriatrics: Impact on professional practice. International Journal of Medical Informatics, 82(8), 684–695. https://doi.org/10.1016/j.ijmedinf.2013.04.006
Geoffroy, O., Acar, P., Caillet, D., Edmar, A., Crepin, D., Salvodelli, M., Dulac, Y., & Paranon, S. (2008). Videoconference pediatric and congenital cardiology consultations: A new application in telemedicine. Archives of Cardiovascular Diseases, 101(2), 89–93. https://doi.org/10.1016/S1875-2136(08)70264-X
Goffman, E. (1981). Forms of Talk. Philadelphia: University of Pennsylvania Press.
Goodwin, C. (1979). The Interactive Construction of a Sentence in Natural Conversation. In G. Psathas (Ed.), Everyday Language: Studies in Ethnomethodology (pp. 97–121). New York: Irvington Publishers.
Goodwin, C. (1981). Conversational organization: Interaction between speakers and hearers. New York: Academic Press.
Goodwin, C. (2000). Action and embodiment within situated human interaction. Journal of Pragmatics, 32(10), 1489–1522. https://doi.org/10.1016/S0378-2166(99)00096-X
Goodwin, C. (2007). Participation, stance and affect in the organization of activities. Discourse & Society, 18(1), 53–73. https://doi.org/10.1177/0957926507069457
Goodwin, C. (2013). The co-operative, transformative organization of human action and knowledge. Journal of Pragmatics, 46(1), 8–23. https://doi.org/10.1016/j.pragma.2012.09.003
Goodwin, C. (2018). Why Multimodality? Why Co-Operative Action? (transcribed by J. Philipsen). Social Interaction. Video-Based Studies of Human Sociality, 1(2). https://doi.org/10.7146/si.v1i2.110039
Greenhalgh, T., Vijayaraghavan, S., Wherton, J., Shaw, S., Byrne, E., Campbell-Richards, D., Bhattacharya, S., Hanson, P., Ramoutar, S., Gutteridge, C., Hodkinson, I., Collard, A., & Morris, J. (2016). Virtual online consultations: Advantages and limitations (VOCAL) study. BMJ Open, 6(1), e009388. https://doi.org/10.1136/bmjopen-2015-009388
Greer, T. (2016). Learner initiative in action: Post-expansion sequences in a novice ESL survey interview task. Linguistics and Education, 35, 78–87. https://doi.org/10.1016/j.linged.2016.06.004
Greer, T. (2018). Learning to say grace. Social Interaction. Video-Based Studies of Human Sociality, 1(1). https://doi.org/10.7146/si.v1i1.105499
Hall, J. K., Hellermann, J., & Pekarek Doehler, S. (2011). L2 Interactional Competence and Development. Channel View Publications. http://ebookcentral.proquest.com/lib/kbdk/detail.action?docID=837799
Hassert, Liv Otto; Nielsen,Mie Femø; Nielsen, Ann Merrit Rikke. (2016). Møder via video, web eller telefon. In Kommunikation i internationale virksomheder (Vol. 1, pp. 173–202). Copenhagen: Samfundslitteratur.
Have, P. ten. (1989). 6. The Consultation as a Genre. In Text and talk as social practice. Discourse difference and division in speech and writing (Reprint 2016, Vol. 2). Den Haag: De Gruyter Mouton. https://doi.org/10.1515/9783111684369-008
Heath, C. (1981). The opening sequence in doctor-patient interaction. In P. Atkinson & C. Heath (Eds.), Medical work: Realities and routines (pp. 71–90). Gower: Farnborough.
Heath, C. (Ed.). (1986). Forms of participation. In Body Movement and Speech in Medical Interaction (pp. 76–98). Cambridge: Cambridge University Press. https://doi.org/10.1017/CBO9780511628221.006
Hellermann, J. (2007). The Development of Practices for Action in Classroom Dyadic Interaction: Focus on Task Openings. The Modern Language Journal, 91(1), 83–96. JSTOR. https://www.jstor.org/stable/4127089
Heritage, J., & Maynard, D. W. (2006). Introduction: Analyzing interaction between doctors and patients in primary care encounters. In Heritage, J. & Maynard, D. W. (eds): Communication in medical care, interaction between primary care physicians and patients (p. 21). Cambridge: Cambridge University Press.
Jacoby, S., & Ochs, E. (1995). Co-Construction: An Introduction. Research on Language and Social Interaction, 28(3), 171–183. https://doi.org/10.1207/s15327973rlsi2803_1
Jefferson, G. (2004). Glossary of transcript symbols with an introduction. In G. H. Lerner (Ed.), Conversation Analysis: Studies from the first generation (pp. 13–31). Amsterdam/Philadelphia: John Benjamins Publishing Co.
Kidwell, M., & Zimmerman, D. H. (2007). Joint attention as action. Journal of Pragmatics, 39(3), 592–611. https://doi.org/10.1016/j.pragma.2006.07.012
Lee, Y.-A., & Hellermann, J. (2014). Tracing Developmental Changes Through Conversation Analysis: Cross-Sectional and Longitudinal Analysis. TESOL Quarterly, 48(4), 763–788. JSTOR. https://www.jstor.org/stable/43268016
Levinson, S. C. (1988). Putting linguistics on a proper footing: Explorations in Goffman’s participation framework. In P. Drew & A. Wootton (Eds.), Goffman: Exploring the interaction order (pp. 161–227). Oxford: Polity Press.
Lundvoll Nilsen, L. (2011). Collaborative Work by Using Videoconferencing: Opportunities for Learning in Daily Medical Practice. Qualitative Health Research, 21(8), 1147–1158. https://doi.org/10.1177/1049732311405683
Markee, N. (2008). Toward a Learning Behavior Tracking Methodology for CA-for-SLA. Applied Linguistics, 29(3), 404–427. https://doi.org/10.1093/applin/amm052
Martin, C., & Sahlström, F. (2010). Learning as Longitudinal Interactional Change: From Other-Repair to Self-Repair in Physiotherapy Treatment. Discourse Processes, 47(8), 668–697. https://doi.org/10.1080/01638531003628965
Maynard, D. W., & Heritage, J. (2005). Conversation analysis, doctor–patient interaction and medical communication. Medical Education, 39(4), 428–435. https://doi.org/10.1111/j.1365-2929.2005.02111.x
Melander, H., & Sahlström, F. (2009). Learning to Fly—The Progressive Development of Situation Awareness. Scandinavian Journal of Educational Research, 53(2), 151–166. https://doi.org/10.1080/00313830902757576
Mlynář, J., González-Martínez, E., & Lalanne, D. (2018). Situated organization of video-mediated interaction: A review of ethnomethodological and conversation analytic studies. Interacting with Computers, 30(2), 73–84. Scopus. https://doi.org/10.1093/iwc/iwx019
Mondada, L. (2007). Multimodal resources for turn-taking: Pointing and the emergence of possible next speakers. Discourse Studies, 9(2), 194–225. https://doi.org/10.1177/1461445607075346
Mondada, L. (2015). Ouverture et préouverture des réunions visiophoniques. Reseaux, n° 194(6), 39–84. https://www.cairn.info/revue-reseaux-2015-6-page-39.htm
Nguyen, H. thi. (2012). Introduction. In H. thi Nguyen (Ed.), Developing Interactional Competence: A Conversation-Analytic Study of Patient Consultations in Pharmacy (pp. 1–13). Palgrave Macmillan UK. https://doi.org/10.1057/9780230319660_1
Nguyen, H. thi. (2017). Toward a Conversation Analytic Framework for Tracking Interactional Competence Development from School to Work. In S. Pekarek Doehler, A. Bangerter, G. de Weck, L. Filliettaz, E. González-Martínez, & C. Petitjean (Eds.), Interactional Competences in Institutional Settings: From School to the Workplace (pp. 197–225). Springer International Publishing. https://doi.org/10.1007/978-3-319-46867-9_8
Nielsen, L. O., Krebs, H. J., Albert, N. M., Anderson, N., Catz, S., Hale, T. M., Hansen, J., Hounsgaard, L., Kim, T. Y., Lindeman, D., Spindler, H., Marcin, J. P., Nesbitt, T., Young, H. M., & Dinesen, B. (2017). Telemedicine in Greenland: Citizens’ Perspectives. Telemedicine and E-Health, 23(5), 441–447. https://doi.org/10.1089/tmj.2016.0134
PAconsulting. (2018). Analyse af skærmbesøg og virtuelle konsultationer (p. 83). Digitaliseringsstyrelssen.
Pappas, Y., & Seale, C. (2009). The opening phase of telemedicine consultations: An analysis of interaction. Social Science & Medicine, 68(7), 1229–1237. https://doi.org/10.1016/j.socscimed.2009.01.011
Pekarek Doehler, S., & Petitjean, C. (2017). Introduction: Interactional Competences in Institutional Settings – Young People Between School and Work. In S. Pekarek Doehler, A. Bangerter, G. de Weck, L. Filliettaz, E. González-Martínez, & C. Petitjean (Eds.), Interactional Competences in Institutional Settings: From School to the Workplace (pp. 1–26). Springer International Publishing. https://doi.org/10.1007/978-3-319-46867-9_1
Pekarek Doehler, S., Wagner, J., & González-Martínez, E. (2018). Longitudinal Studies on the Organization of Social Interaction. Palgrave Macmillan Limited. http://ebookcentral.proquest.com/lib/kbdk/detail.action?docID=5316909
Petersen, M. S., Morris, D. J., & Nielsen, M. F. (2016). A pilot study of telehealth and face-to-face consultations in diagnostic audiology. CIRCD Working papers in social interaction, 1(3), 1-38. Centre of Interaction Research and Communication Design, University of Copenhagen ISBN 978-87-93300-10-1
Rasmussen, G. (2016). Repeated use of request for confirmation in atypical interaction. Clinical Linguistics & Phonetics, 30(10), 849–870. https://doi.org/10.1080/02699206.2016.1209244
Raudaskoski, P. L. (1999). The Use of Communicative Resources in Language Technology Environments: A Conversation Analytic Approach to Semiosis at Computer Media. Oulu: Åbo Akademis Tryckeri. https://vbn.aau.dk/en/publications/the-use-of-communicative-resources-in-language-technology-environ
Robinson, Jeffrey D., & Heritage, J. (2005). The structure of patients’ presenting concerns: The completion relevance of current symptoms. Social Science & Medicine, 61(2), 481–493. https://doi.org/10.1016/j.socscimed.2004.12.004
Robinson, Jeffrey David. (1998). Getting Down to Business Talk, Gaze, and Body Orientation During Openings of Doctor-Patient Consultations. Human Communication Research, 25(1), 97–123. https://doi.org/10.1111/j.1468-2958.1998.tb00438.x
Rossano, F., Brown, P., & Levinson, S. C. (2009). Gaze, questioning, and culture. In J. Sidnell (Ed.), Conversation Analysis: Comparative Perspectives (pp. 187–249). Cambridge: Cambridge University Press. https://doi.org/10.1017/CBO9780511635670.008
Sacks, H. (1984). On doing “being ordinary.” In J. M. Atkinson & J. Heritage (Eds.), Structures of Social Action: Studies in Conversation Analysis (pp. 413–429). Cambridge: Cambridge University Press. https://doi.org/10.1017/CBO9780511665868.024
Sacks, H., Schegloff, E. A., & Jefferson, G. (1974). A Simplest Systematics for the Organization of Turn-Taking for Conversation. Language, 50(4), 696. https://doi.org/10.2307/412243
Sävenstedt, S., Zingmark, K., & Sandman, P.-O. (2004). Being Present in a Distant Room: Aspects of Teleconsultations with Older People in a Nursing Home. Qualitative Health Research, 14(8), 1046–1057. https://doi.org/10.1177/1049732304267754
Schegloff, E. A. (1979). Identification and Recognition in Telephone Conversation Openings. In G. Psathas (ed.) Everyday Language: Studies in Ethnomethodology, pp. 23–78. New York: Irvington .
Schegloff, E. A. (1985). On some gestures’ relation to talk. In J. M. Atkinson (Ed.), Structures of Social Action (pp. 266–296). Cambridge: Cambridge University Press. https://doi.org/10.1017/CBO9780511665868.018
Schegloff, E. A., Jefferson, G., & Sacks, H. (1977). The Preference for Self-Correction in the Organization of Repair in Conversation. Language, 53(2), 361. https://doi.org/10.2307/413107
Suchman, L. (2009). Human-machine reconfigurations: Plans and situated actions / (2. ed., reprint.). Cambridge: Cambridge University Press.
van den Berg, N., Schumann, M., Kraft, K., & Hoffmann, W. (2012). Telemedicine and telecare for older patients—A systematic review. Maturitas, 73(2), 94–114. https://doi.org/10.1016/j.maturitas.2012.06.010
Wagner, J., Pekarek Doehler, S., & González-Martínez, E. (2018). Longitudinal Research on the Organization of Social Interaction: Current Developments and Methodological Challenges. In S. Pekarek Doehler, J. Wagner, & E. González-Martínez (Eds.), Longitudinal Studies on the Organization of Social Interaction. Palgrave Macmillan Limited.
Webb, H., Lehn, D. vom, Heath, C., Gibson, W., & Evans, B. J. W. (2013). The Problem With “Problems”: The Case of Openings in Optometry Consultations. Research on Language and Social Interaction, 46(1), 65–83. https://doi.org/10.1080/08351813.2012.753724
Zimmerman, D. H. (2008). Identity, Context and Interaction. In Identities in Talk (pp. 88–106). London: SAGE Publications Ltd. https://doi.org/10.4135/9781446216958.n6