Social Interaction
Video-Based Studies of Human Sociality
“Difficult to assess in this manner”: An “ineffective” showing sequence in post-surgery video consultation
Wyke Stommel1, Christian Licoppe2 & Martijn Stommel1
1Radboud University
2Telecom Paristech
Abstract
There is a growing interest in telecare, particularly in the kind of “invisible work” involved in teleconsultations (Oudshoorn, 2011). One dimension of this work is the “sensory work” in support of clinical examination at a distance (Lupton & Maslen, 2017). More research is needed to understand how such sensory work is done in and as multimodal interaction (Mondada, 2019). Recent work has shown the extent to which such sensory work could be re-mediated, despite challenges due to the technology, in particular the asymmetry of sensory access (Seuren et al., 2020; Stommel, Van Goor, & Stommel, 2020). In earlier research, we found that showings occurred less frequently in post-surgery consultations conducted through video rather than face-to-face (Stommel et al., 2020). Moreover, in spite of the apparent relevance of visual access, it seemed as if showings were even being evaded. In this article, we use a conversation analytical perspective to examine one case of emergent showing sequences in a video-mediated post-surgery consultation, in order to track its sequential organisation, which develops towards an eventually inadequate showing. The case comes from a set of post-surgery consultations with patients who had undergone tumour resection (abdominal surgery) two weeks earlier. We first present a case from an in-person consultation, in which a showing sequence is inserted smoothly and closed with mutual assessments. Next, we focus on the VMC-showing, which is also inserted in the context of a patient question concerning the surgery scars. We analyse the context leading up to the showing, the showing itself and the abandonment of the showing sequence. We found that, first, the showing is not initiated at the earliest sequential opportunity, but is requested with an orientation to potential barriers. Second, screen-based evidential boundaries emerge, as the surgeon has no visual access to what is shown, in response to which the surgeon employs remedial action. Third, the surgeon moves out of the showing to an instructed touch-sequence – in other words, displays of visual appreciation are neither produced nor pursued. Upon the surgeon’s closing formulation that it was “difficult to assess in this manner”, the contextual factor of visibility is eventually explicitly claimed to be “ineffective” for medical assessment. These findings might explain the scarcity of showing sequences in our data. More generally, they raise questions about (the limits of) sensory work in video consultations.
Keywords: videomediated interaction, multimodal interaction, telecare, conversation analysis, showing
1. Introduction
While the potential of video-mediated communication to provide “care at a distance” (Pols, 2012) is increasingly explored (e.g. Atherton et al., 2018), questions can be raised regarding clinical examination, which usually relies on the physician’s access to the body, and visual and tactile access in particular (Heritage, 2017). The lack of such perceptual access, for instance via phone-based audio-consultations, leads to “telling”-oriented sequences, in which the patient is instructed to describe medical relevancies to the remote health professional (Lopriore, LeCouteur, Ekberg & Ekberg, 2019). Video-mediated communication (VMC) represents an intermediate case in which some degree of visual access may be managed collaboratively, although this may involve significant work from the co-participants, which may also fail (Seuren et al., 2020). In this article, we present a single case analysis of a showing sequence in the VMC-setting, after which the surgeon concludes that direct visual access is required to assess the problem. The aim is to track the sequential unfolding of an ineffective showing in the post-surgical VMC setting.
2. Physical examination in VMC medical consultation
Generally, physical examination has been identified as one of the challenges of medical video consultation (Donaghy et al., 2019; Greenhalgh et al., 2018; Seuren et al., 2020). It constitutes part of the sensory work relevant to care at a distance (Lupton & Maslen, 2017). Some challenges are related to the patients’ self-examination in front of the camera, such as taking measurements of weight, blood pressure, heart rate and rhythm, and oxygen saturation; while others are related to the physician’s visual access. In a recent study of post-surgery consultations, we compared face-to-face consultations with video-mediated ones, and found that in video consultations surgeons arrive at qualified assessments that indicate a degree of uncertainty as a result of reliance on patient reports and observations of their closed wounds (Stommel et al., 2020). Furthermore, it appeared that showing the scar was a rare practice in post-surgery video consultations compared to co-present consultations, as can be seen in Table 1, taken from Stommel et al. (2020).
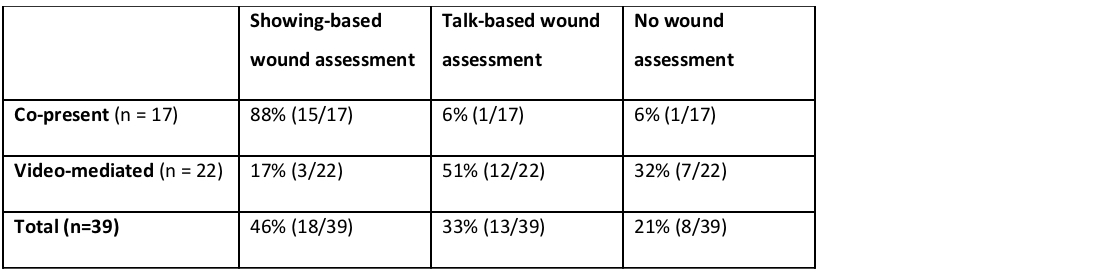
In the case of a patient question or potential trouble report, visual access did appear relevant, but the opportunity for showing was not always employed, leading to a lengthy series of questions and answers circumventing what potentially could have been shown (or, in a co-present setting, palpated) (Stommel et al., 2020). This could explain why prior studies on the physician’s perspective on the applicability of video consultations revealed an anticipated need for physical examination as a main reason not to opt for video consultation (Donaghy et al, 2019; Greenhalgh et al., 2018). However, visual access is an affordance (Hutchby, 2001) of video consultation compared to, for instance, telephone calls. The question is whether the scarcity of showings can be understood by tracking the collaborative sequential unfolding of these showings, especially when the showing sequence is abandoned. Do participants orient to problems in the course of such sequences – and if so, what are these (indices of) problems? In this paper, we focus on one consultation in which visual access to the patient’s body becomes relevant for medical assessment, but in which the showing is eventually claimed to have been ineffective.
3. Showing sequences
Previous research on showing sequences, inspired by ethnomethodology and conversation analysis, has identified a typical or canonical three-part organisation for such sequences: an initiation phase, a manipulation phase and a closing phase (Licoppe, 2017). In the initiation phase, participants steer the focus of the interaction towards an object by making it perceptually relevant in a certain way, for instance through a preface (Licoppe & Tuncer, forthcoming) or request sequences (Mondada, forthcoming). Objects can thus be framed so that the showing is oriented towards visual identification or recognition, as in “informative showings”, or towards appreciation and assessment, as in “evocative showings” (Licoppe, 2017). The initiation sequence provides a setting for the object to be manipulated in order to make it available for public scrutiny, so that it becomes “progressively witnessable and discourseable” (Garfinkel, Lynch, & Livingstone, 1981, p. 138).
In the manipulation phase, the visual emergence of a discoverable object (through its manipulation) is guided, in the sense that it is to be perceived by the recipient(s) in a way that will be adequate enough for all practical purposes, in relation to the way the object has initially been framed as a “showable”. In this phase, the ordinary organisation of the conversational sequence is suspended (this is one of the sequential functions of the initiation phase). Should some talk occur there, it is expected that it would be designed and treated as accountable with respect to the moment-by-moment consideration and manipulation of the object, in terms of both sequential positioning and topicality. This particular articulation of actions oriented towards the local perceptual-material ecology, sequentials and topical constraints on talk are characteristic of showing sequences and, more generally, of object-centered sequences (Tuncer, Licoppe, & Haddington, forthcoming).
In the closing phase, participants orient towards the relevance of displaying that they have achieved a joint visual grasp of the object that is, for all practical purposes, adequate (Licoppe, 2017). This is usually achieved through recognition tokens and assessment sequences. Indeed, this particular sequential configuration is a privileged site for assessment sequences (Fasulo & Monzoni, 2009; Oshima & Streeck, 2015; Searles, 2018). Such an assessment may be relevant in a medical context (Heritage, 2017; Ten Have, 1991). Talk in that position is therefore accountable with respect to the kind of interactional project enacted in the showing sequence, i.e. for the recipient to achieve an adequate grasp of the relevant object, here and now. It is readily available to be interpreted as a display of the kind of perceptual alignment the recipient has achieved with the object, and its relevance to the initial framing of the latter. Such displays may then either be treated as opportunities to move on topically and sequentially, for instance to discuss the object itself or to introduce some other topic and return to the sequential organisation of ordinary conversation. Such displays may also be treated as reasons to continue with the showing sequences, which is a way to treat such responses as displaying inadequate alignment and potentially cueing trouble.
4. Showing sequence and sequential stances
In CA, the notion of “stance” is used to describe the kind of alignment participants may have with respect to current foci of interactional concern (see e.g. Goodwin, 2013). Here, we would like to extend this to larger sequences, such as “object-centered sequences” in general (Tuncer & Haddington, 2020), and showing sequences in particular. The idea is that just as a context-independent, recognisable sequence of interaction may be deployed in a context-sensitive way, participants may display different types of alignment (stances) regarding the way in which such sequences may unfold, and what may be achieved in their course. Showing sequences, and the particular orientation towards embodied manipulation and talk, create a sequential opportunity for recipients to claim or display that they have “seen” the showable under a certain aspect, and make that relevant to the unfolding interaction. If nothing of the sort recognisably arises at this juncture – such as an appreciative receipt or merely an acknowledgement – then it may be pursued, and therefore appear to be treated as missing, as is often the case in showings conducted via interpersonal Skype calls (Licoppe, 2017). Although it is difficult to support the claim that a response was relevant when the participants do not locally treat it as “absent” (Schegloff, 2007, p. 21), a lack of response may still be noticeable. Physicians have been found to respond to new information with, for example, assessments or neutral responses (“I see”, “okay”) (Ten Have, 1991). This renders a lack of response to an informative showing noticeable. A sequential stance to the showing may also be found to be detached from the actual showing sequence, similar to how a diagnosis may be provided at some interactional distance from the physical examination on which it is based (Peräkylä, 1998). We therefore propose that the absence of a response to a showing and/or a detached assessment of the showing may constitute a sequential stance to the effectiveness of the showing, in terms of having accomplished the provision of visual access to the showable.
In this article, we focus on one of the rare cases of showing the surgery scar from our data. Our aim here is to gain new insight into the challenges of physical examination and showing practices in medical video consultations. We chose this case because the surgeon eventually claims the complaint is difficult to assess “in this manner”, and proposes to instead examine the patient at the hospital. Our analysis shows that the surgeon takes a negative stance towards the showing, in terms of how it is initiated, how it is not acknowledged and in his concluding claim about the showing through video. However, by way of contrast, we first present a showing sequence from a co-present consultation that illustrates how uncomplicated a showing and assessment can be (cf. Due, Lange, Nielsen, & Jarlskov, 2019).
5. Data and methods
We recorded 22 video consultations and 17 co-present consultations with patients who underwent abdominal tumor resection. In most cases, one or two family members were present at the consultation. The purpose of the consultations, which took place roughly two weeks after surgery, was to discuss the findings of the pathology tests and enquire as to the patient’s recovery (Stommel, Van Goor, & Stommel, 2019), including questions concerning activity, eating and drinking, defecation and the healing of the surgery scars. The recordings were made at the hospital, with one camera directed at the surgeon’s screen (desktop computer) and one at the surgeon. One implication of this set-up is that we have no access to the patient’s screen and surroundings. As a consequence, possible transmission delays cannot be checked from the perspective of the patient. Similarly, we lack information on the device used by the patient and on the presence of a control screen, which could be relevant when trying to show something to the co-participant. However, as control screens are a standard feature of the software used (a program called Facetalk), and as the patient in the case we present here never verbally checked whether the physician could see them, we may tentatively assume a control screen was available. The surgeons also had a control screen and a second desktop screen to the left of the video connection screen, which showed the patient’s medical file.
Three out of the 22 video-consultations included some sort of showing sequence. This means that showings are rare in our video-consultation data compared to co-present consultations of the same type (Stommel et al., 2020). First, we examined all three cases to get a sense of their interest in each of the consultations. One showing request occurred in the context of a patient report by a nurse who had claimed the patient’s wound had healed beautifully. The showing itself was produced swiftly, almost messily, barely giving visual access to the object of interest, but nevertheless culminated in a colloquial positive assessment and a self-praise joke by the surgeon. The two other sequences seemed sequentially more familiar: the showing requests were inserted after a patient question and/or potential trouble mention. Because of the particular institutional implications and medical relevance of the requested showings in the context of potential trouble, we focus on the one case in which the showing was eventually insufficient for a conclusive assessment of the problem.
We used a CA-inspired, comparative ethnographic approach, with a particular focus on sequence organisation (Schegloff, 2007) and multimodal analysis (Mondada, 2014; Stivers & Sidnell, 2005), to examine whether there are indices in the sequential accomplishment of a showing in a video consultation that the participants (particularly the surgeon) orient to it as ineffective. Based on an understanding of the various options that the sequential organisation of showing sequences projects as relevant (and which are available to participants on the basis of their everyday competences), we develop a “third-party” analysis of potential differences between settings in the use of such sequences. We use transcription conventions to represent talk in its multimodal orchestration (Mondada, 2018), and Author 1 translated the excerpts.
6. A showing sequence in co-present consultation
In our data, showing sequences were common in co-present consultations, as in Excerpt 1. The patient’s partner initiates a question about the stitches towards the end of the consultation (line 1). We use PAR for partner, PAT for patient and SUR for the surgeon.
The question about the stitches – initiated by the partner, but continued by the patient herself (lines 2-3) – introduces the stitches, which are potentially available perceptually. Mentioning something present and viewable provides participants with an opportunity to look at it. Indeed, before a transition-relevant point is reached, the surgeon points at the patient’s belly and proposes to “very briefly look at the wound” (line 4) in overlap. Hence, the requested showing appears to be initiated as a “touched-off” showing (Licoppe & Tuncer, forthcoming), made relevant by the discussion of the stitches, which are potentially made visually available and as such are showable. In our data, doctors seem to orient readily to the visual consideration of the scars – sometimes requesting it, sometimes seizing the opportunity when it becomes relevant, as here.
This proposal is formatted in straightforward manner, lacking any modal verb (can I, may I), hence orienting to “having a look” as a low-contingency request (Curl & Drew, 2008) and a routine activity in this setting (see also Stommel et al., 2020). The patient, despite the presence of the camera, immediately accepts it and starts lifting her shirt to expose her belly (line 5), while the surgeon adds an instruction of how to comply (“just lift the shirt like this”, line 6). Now leaning forward over the table, the surgeon confirms what was left implicit in the patient’s question, namely that the stitches are self-resolvable. This response marks the showing as complete, which is underscored by the retraction of the surgeon’s torso back into his chair before the end of the turn (line 8). The patient’s continuer (line 9) invites a verbal elaboration, while her bodily behaviour – pulling her shirt down – confirms the completeness of the showing sequence. The surgeon then produces a positive assessment of the wound/stitches (“looks neat” line 10). Such an assessment is interesting in the sense that it is hearable as both a lay expression and a medical one. If it is heard as a lay one, then seeing the scar that way is also available to all the participants present. There is no epistemic asymmetry, and the showing sequence therefore presents an opportunity for the participants to claim and display that they “see” the showable in the same way. In this way, the patient aligns with the surgeon’s assessment by agreeing, starting to repeat it and upgrading it (line 11), which the surgeon in turn confirms (line 12).
In brief, we can say that the showing sequence is initiated in a rather straightforward manner, that it runs smoothly in terms of giving visual access, and is completed with unequivocal assessments. It is therefore completed as a routine collaborative achievement. The fact that the patient shows her scar in this environment displays some measure of trust that an actual showing might be effective with respect to current interactional concerns. However, in the VMC environment, a showing sequence may encompass extended collaborative work and fail to arrive at mutually agreed assessments.
In contrast to the co-present example, showing in the VMC setting does not seem to run smoothly and routinely. In the following analysis, we try to pinpoint interactional constraints in the collaborative achievement of a VMC showing. This case involves a female patient who underwent liver tumour resection approximately two weeks before the consultation. She is a non-native speaker of Dutch, whose first languge is Italian. With this patient, keyhole surgery was carried out initially, but appeared unsuccessful during the operation, which resulted in the surgeon having to make a larger incision. As a result, the patient has both keyhole surgery scars and a larger closed wound. In this case, the patient is eventually invited to come to the hospital for “live” examination, which implies the showing was inadequate in occasioning an assessment. In the following, we will track the unfolding of this showing sequence from its beginning. The showing becomes relevant in the context of a question from the patient after the test results have been discussed, and after the surgeon asked several questions about the patient’s recovery, including one about the closed wound. The patient claimed she checked it that morning and it was healing very well.

After having discussed the patient’s recovery, concluding a last question about eating, the surgeon asks the open question “DID YOU MAYBE HAVE QUESTIONS FOR ME?” (line 1). By design and placement, this turn can be understood as a generic “topic initial elicitor” (Button & Casey, 1985). In terms of positioning, it segments the conversation and the consultation, marking the exhaustion of the previous sequence of talk, while also offering a slot in which to report some potential “mentionables”. The nature of those is left both open and bounded – in other words, it could be anything that appears relevant to this consultation at this point. The modality (“maybe”) also displays that nothing is available to raise as a relevant topic, and at this point this would also be admissible and mark a step towards closing the consultation (Schegloff & Sacks, 1973). After a marked silence and delay, the patient provides an answer with two distinct turn-construction units (TCU). The first TCU mentions a location on her body (“near my right lung”, line 3). This is done somewhat tentatively, with a kind of repair/word search in the middle. It is followed by a second TCU, which highlights a mentionable that is also a potential “viewable” on her body (“I have two red scars”). After an agreement token from the surgeon, the patient provides an elaboration of her earlier turn, namely an interrogation about what the surgeon did at that location on her body (line 7). She goes on by providing a kind of candidate answer, uttered in an interrogative tone (the reference to keyhole surgery, line 8). By making relevant not only a location and a scar, but the past activity of the recipient regarding them, packaged into a kind of yes/no-question, she projects further talk from the recipient as a next-positioned matter (confirmation and accounting in particular). However, after a brief silence, the surgeon does not produce what was projected by the question, but rather inserts a showing request (“can you maybe show it to me?”, line 10), the possibility of which had been opened in the earlier turn in lines 3–4. The “can you X” design of the showing request displays entitlement, while orienting to potential contingencies (Curl & Drew, 2008). Note however, that the request is hedged (“maybe”), thereby orienting at a potential barrier or imposition in the request. Furthermore, the surgeon elaborates the request after a pause, adding “with the camera”, and thus hinting at potential practical issues in the achievement of the showing.
The sequential positioning of the showing request, coming not around line 6 after the initial mention of “viewables”, but after a later clarification question, frames the showing sequence it projects in a particular way. The projected showing sequence can be understood as an inserted sequence and as a resource within a larger activity (answering the question in lines 7–8), rather than as an end in itself (as might have appeared to be the case had it been initiated after the mention of a showable, as a “touched-off” showing sequence). Finally, note that the deictic “it” in the request (line 10) does not resolve the initial ambiguity regarding showing a location on the body versus showing a viewable/assessable matter, such as red scars. The next excerpts include the patient’s response to the showing request.
The patient complies with the request, thus embarking on the collaborative activity of showing. She manipulates the camera and brings her finger to the spot for two seconds. Then, she produces a token of agreement (which may work as a second pair part for the request to show), followed by “so here” (line 13). While “so” in the initial position marks the timing of her achievement, “here” indexes a location. Her talk is combined with her putting her finger on the spot, in an “environmentally-coupled gesture” (Goodwin, 2007), so that both are mutually elaborative. She thus achieves a kind of pointing, towards a just-found visual relevancy. It is interesting to note that her behaviour is oriented towards showing a location on her body, rather than something to be viewed on it, since she does not lift her shirt. She thus disambiguates between the spot near the lungs and the two red scars as the focus of interest. However, her hand and the spot she touches with it are too low to be visible on screen. The surgeon provides a noticing of this, framed as a negative (line 15), and thus hearable as a trouble initiator (Schegloff, 1988). This understanding is reinforced by a further elaboration in which he offers a candidate remedial action, designed as a request to move the camera down (line 15). She recoils and rearranges her posture for over 14 seconds, before finally managing it, and telling so (line 19). This collaborative remedial work and the patient’s durable rearrangement breaks the progressivity of the showing sequence. Compared to the smooth flow of the showing in Excerpt 1, it shows how the mediation of the camera, along with the introduction of screen-mediated “evidential boundaries” in the situation, makes the collaborative accomplishment of showing sequences more vulnerable to visual intersubjectivity trouble than in co-present environments.
It is worth remarking on the particular organisation of talk and embodied conduct in this sequence. The compliance with the request to show initiates a sequence that is, while interactional, no longer “conversational”, in the sense that: a) talk, when it occurs, is produced as occasioned by embodied conduct oriented towards potential showables; and b) such talk is systematically oriented towards the visual-embodied activity, whether it marks having managed a potential showing (as with the patient in lines 13 and 19) or the surgeon making visible some visual trouble (which also projects some more embodied activity). As such, showing sequences, once launched, involve a suspension of the organisation of conversation (Licoppe, 2017), which could be considered as a multimodal analogue of what occurs with storytelling (Sacks, 1992). This kind of reorganisation of talk and embodied conduct is generally more characteristic of “object-centered sequences” (Tuncer & Haddington, forthcoming).
The turn at lines 21–22 abandons this showing sequence in several respects. The initial TCU “and now” operates to signal the start, at this juncture, of something different. The following TCU is designed as a yes/no-question about whether the patient feels her rib at the spot she is touching. In itself, the question projects talk that is conditional to particular embodied actions, but in a very different way than with the showing sequence. Instead of a showing request that presupposes the possibility of visual access, even at a distance, the sense of touch can only reported by the “toucher”. The surgeon’s question then inaugurates an “instructed touch sequence”, in which he may ask questions such as this one, and the patient touches her body so as to produce a relevant answer and describe her experience to him (data not shown).
It is interesting to note that the closing of prototypical showing sequences, as we have discussed above, is usually initiated by turns that display that the recipient has recognised and/or appreciated a showable and has seen it under a certain aspect (Fasulo & Monzoni, 2009; Oshima & Streeck, 2015; Raclaw, Robles, & Didomenico, 2016). This is a common sequential position for assessments, and also offers a slot for other participants to align (or not) with the visual appreciation in order to display that an adequate degree of (visual) intersubjectivity has been established (or not). However, there is none of that here, not even a minimal response token (Gardner, 2001) that would at least display the recipient’s understanding that something has been achieved visually, while orienting to next-positioned matters. While he has a sequential opportunity to do so here, the surgeon gives no sign that he has been able to “see” something in a relevant way, i.e. from a medical perspective (cf. Ten Have, 1991). Hence, the turn in lines 21–22 abandons the pursuit of a proper showing by proposing an alternative “route” for the achievement of an adequate assessment.
After the instructed touch sequence (data not shown), the surgeon claims the ineffectiveness of the examination, and thus his inability to answer the patient’s question.
The surgeon marks the previous sequence as ended (the initial position “okay (.) fine”, line 57), and moves on to a retrospective assessment or diagnosis. This takes the form of a formulation (Heritage & Watson, 1979) that precisely highlights the question of the effectiveness of the inserted showing (and touching) sequence, in which the patient showed her scar on screen: “yes that is still in this manner difficult to assess”. This inconclusive assessment is detached from the showing sequence and explicates the lack of evidence (cf. Peräkylä, 1998), which leads to the proposal for a subsequent (in person) appointment for the surgeon to “still take look”. With this negative formulation, the surgeon thus takes a negative “stance” – he displays a kind of mistrust regarding the effectivity of the showing sequence that has been achieved “in this manner”. As an indexical, “in this manner” inferences the VMC-setting. Since the stance here bears on a particular, recognisable type of sequence (here, a VMC-mediated showing sequence), we call this a “sequential stance”. In fact, the recognisability of a showing sequence (or any type of sequence) as such, and that of displaying a particular stance with respect to it as an accomplishment are two aspects of one and the same thing. As such, this formulation shows the interplay of showing sequences and assessments of the potential problem in which lack of evidence is implicitly referenced. However, the lack of evidence here covers not only what could not be seen, but also what was not shown via VMC, indicating that the “showable” has to be manipulated in front of the camera to be “seen” by the surgeon.
7. Conclusion
Starting from the empirically observable fact that showing sequences were much rarer in a particular type of post-surgery VMC-mediated consultations than in co-present ones, we examined one of those rare cases in which a doctor wraps up an examination of visible scars by taking a negative stance regarding the effectiveness of attempting that kind of assessment in the VMC environment. We observed two features which may be characteristic of VMC showing sequences. First, the progressivity of showing sequences could be hindered by trouble initiation regarding the on-screen visibility of some relevant visual features, and remedied with embodied reconfigurations and camera work. Second, just before the activity moves away from the consideration of a showable (a moment that retrospectively marks the closing of a showing sequence), an acknowledgement or assessment by the surgeon of “seeing” the showable was absent, even though this would be a sequential opportunity for such a response (cf. Ten Have, 1991). The abandoning of the showing sequence and the initiation of an instructed touch sequence indicate that the showing was inadequate. What happens here could be described as “passing a sequential opportunity to display some relevant form of seeing”, which is recognisable to participants on the basis of their familiarity with the routine organisation of showing sequences, even if they do not directly orient to that as a source of trouble. On the basis of this single case analysis, our hypothesis is that “showing without seeing” is one of the challenges of VMC consultations, and provides a potential explanation for the scarcity of showing sequences in our data set.
This means that showing sequences in VMC are rather different from a) co-present consultations, where, as we saw in Excerpt 1, doctors straightforwardly provide that kind of display; and b) informal conversations, in which participants tend to pursue such displays when they are not achieved immediately, so as to show that they were both able to adequately see the showable under some locally relevant aspect. This could be related to the medical setting, and the epistemic constraints that are brought to bear on showing sequences in that context. Whereas a showing sequence in the medical setting may purport to elicit some display of “seeing together (cf. Excerpt 1), it may also be oriented to the doctor to see the matter in a medically relevant way that is not available to the show-er (cf. “professional vision”, Goodwin, 1994). From the shower’s perspective, this makes it more difficult to fine-tune embodied conduct to facilitate the doctor’s seeing. From the doctor’s perspective, it might be problematic to try too hard to see something, because should he not manage to see it, his professional capacity could be questioned. Additionally, the more the doctor pursues the matter, the more he would make it salient that he believes that there is something to be seen.
Such features of the way in which showing sequences unfold in VMC consultations might account for the negative stance the surgeon takes and expresses (Excerpt 2) when he deems the scar difficult to assess in this way. This negative stance accentuates the earlier absence of an acknowledgement of the showing. Although the participants did not immediately orient to this absence (the criteria for something missing in CA, Schegloff, 2007), it was more than simply not occurring. Such “weak absence” might give rise to the kind of lingering sense of unachievement that somehow surfaces in such a formulation, an expression of a negative stance with respect to the showing of the scar in VMC. Whether such a stance is a more general feature of VMC consultations requires more data, and data from a variety of telecare settings. However, it might account both for the scarcity of showing sequences in video consultations (the empirical observation that started our investigation), and for the observation that a display of visual appreciation was neither produced nor pursued in the case examined here. Videoconsultation would then not appear to be a congenial environment for this type of sensory work.
References
Atherton, H., Brant, H., Ziebland, S., Bikker, A., Campbell, J., Gibson, A., . . . Salisbury, C. (2018). Alternatives to the face-to-face consultation in general practice: Focused ethnographic case study. British Journal of General Practice, 68(669), e293-e300. doi:10.3399/bjgp18X694853
Curl, T., & Drew, P. (2008). Contingencey and action: A comparison of two forms of requesting. Reseach on Language and Social Interaction, 41, 1-25.
Donaghy, E., Atherton, H., Hammersley, V., McNeilly, H., Bikker, A., Robbins, L., & al., e. (2019). Acceptability, benefits, and challenges of video consulting: a qualitative study in primary care. British Journal of General Practice, 69(686), e586-e594.
Due, B. L., Lange, S. B., Nielsen, M. F., & Jarlskov, C. (2019). Mimicable embodied demonstration in a decomposed sequence: Two aspects of recipient design in professionals' video-mediated encounters. Journal of Pragmatics, 152, 13-27. doi:10.1016/j.pragma.2019.07.015
Fasulo, A., & Monzoni, C. (2009). Assessing mutable objects: a multimodal analysis. Research on Language and Social Interaction, 42(4), 362-376.
Gardner, R. (2001). When listerners talk. Amsterdam: John Benjamins.
Garfinkel, H., Lynch, M., & Livingstone, E. (1981). The work of a discovering science construed with materials from the optically discovered pulsar. Philosophy of the Social Sciences, 11, 131-158.
Goodwin, C. (1994). Professional vision. American Anthropologist, 96(3), 606-633. doi:https://doi.org/10.1525/aa.1994.96.3.02a00100
Goodwin, C. (2007). Environmentally coupled gestures. In S. D. Duncan, J. Cassel, & E. T. Levy (Eds.), Gesture and the Dynamic Dimension of Language: Essays in Honor of David McNeill (pp. 195-212). Amsterdam / Philadelphia: John Benjamins.
Goodwin, C. (2013). The co-operative, transformative organization of human action and knowledge. Journal of Pragmatics, 46(1), 8-23.
Greenhalgh, T., Shaw, S., Wherton, J., Vijayaraghavan, S., Morris, J., Bhattacharya, S., . . . Hodkinson, I. (2018). Real-World Implementation of Video Outpatient Consultations at Macro, Meso and Micro Levels: Mixed Methods Study. Journal of Medical Internet Research, 20(4), e150.
Heritage, J. (2017). Online commentary in primary care and emergency room setting. Acute Medicine & Surgery, 4(12-18). doi:10.1002/ams2.229
Heritage, J., & Watson, D. (1979). Formulations as conversational objects. In G. Psathas (Ed.), Everyday language (pp. 123-162). Hillsday, NJ: Lawrence Erlbaum Associates, Inc.
Hutchby, I. (2001). Conversation and technology: From the telephone to the internet. Cambridge: Polity Press.
Licoppe, C. (2017). Showing objects in Skype video-mediated conversations. From showing gestures to showing sequences. Journal of Pragmatics, 110, 63-82. doi:https://doi.org/10.1016/j.pragma.2017.01.007
Licoppe, C., & Tuncer, S. (forthcoming). The initiation of showing sequences in video-mediated communication. Discourse and Conversation Analysis.
Lopriore, S., LeCouteur, A., Ekberg, K., & Ekberg, S. (2019). 'You'll have to be my eyes and ears': a conversation analytic study of physical examination on a health helpline. Journal of Clinical Nursing, 28(1-2), 330-339.
Lupton, D., & Maslen, S. (2017). Telemedicine and the sense: A review. Sociology of Health & Illness, 39(8), 1557-1571. doi:10.1111/1467-9566.12617
Mondada, L. (2014). The local constitution of multimodal resources for social interaction. Journal of Pragmatics, 65, 137-156.
Mondada, L. (2018). Multiple temporalities of language and body in interaction: Challenges for transcribing multimodality. Research on Language and Social Interaction, 51(1), 85-106. doi:10.1080/08351813.2018.1413878
Mondada, L. (2019). Contemporary issues in conversation analysis: Embodiment and materiality, multimodality and multisensoriality in social interaction. Journal of Pragmatics, 145, 47–62.
Mondada, L. (forthcoming). Participants’ orientations to material and sensorial features of objects: looking, touching, smelling and tasting while requesting products in shops. Discourse and Conversation Analysis.
Oshima, S., & Streeck, J. (2015). Coordinating talk and practical action. The case of hairdressing salon service assessment. Pragmatics & Society, 6(4), 538-564.
Oudshoorn, N. E. J. (2011). Telecare Technologies and the Transformation of Healthcare. Houndmills, Basingstoke, UK: Palgrave Macmillan Ltd.
Peräkylä, A. (1998). Authority and accountability: The delivery of diagnosis in primary health care. Social Psychology Quarterly, 61(4), 301-320.
Pols, J. (2012). Care at a Distance; On the Closeness of Technology. Amsterdam: Amsterdam University Press.
Raclaw, J., Robles, J., & Didomenico, S. (2016). Upgrading epistemic access through mobile devices in face-to-face interaction. Research on Language and Social Interaction, 49(4), 362-379.
Sacks, H. (1992). Lectures on conversation (Vol. 1,2). Oxford: Blackwell.
Schegloff, E. (1988). Goffman and the analysis of conversation. In P. Drew & A. Wootton (Eds.), Erving Goffman: Exploring the Interaction Order (pp. 89-135). Cambridge: Polity Press.
Schegloff, E. (2007). Sequence organization in interaction: A primer in conversation analysis. Cambridge: Cambridge University Press.
Schegloff, E., & Sacks, H. (1973). Opening up closings. Semiotica, 8(4), 289-327.
Searles, D. (2018). ‘Look it Daddy’ Shows in family Facetime calls. Research on Children and Social Interaction, 2(1), 98-119.
Seuren, L., Wherton, J., Greenhalgh, T., Cameron, D., A’Court, C., & Shaw, S. (2020). Physical examinations via video? Qualitative study of video examinations in heart failure, using conversation analysis. Journal of Medical Internet Research, 22(2), e16694. doi:10.2196/16694
Stivers, T., & Sidnell, J. (2005). Introduction: Multimodal Interaction. Semiotica, 156-1/4, 1-20.
Stommel, W., Van Goor, H., & Stommel, M. (2019). Other-attentiveness in video consultation openings: A conversation analysis of video-mediated versus face-to-face consultations. Journal of Computer-Mediated Communication, zmz015. doi:https://doi.org/10.1093/jcmc/zmz015
Stommel, W., Van Goor, H., & Stommel, M. (2020). The impact of video-mediated communication on closed wound assessments in postoperative consultations: conversation analytical study. Journal of Medical Internet Research, 22(5), e17791. doi:10.2196/17791
Ten Have, P. (1991). Talk and institution: a reconsideration of the 'asymmetry' of doctor-patient interaction. In D. Boden & D. Zimmerman (Eds.), Talk and Social Structure: Studies in Ethnomethodology and Conversation Analysis (pp. 138-163). Cambridge, U.K.: Polity Press.
Tuncer, S., & Haddington, P. (2020). Object transfers: An embodied resource to progress joint activities and build relative agency. Language in Society, 49(1), 61-87. doi:10.1017/S004740451900071X
Tuncer, S., Licoppe, C., & Haddington, P. (forthcoming). When objects become the focus of human action and activity: Object-centred sequences in social interaction. Discourse and Conversation Analysis.