 Social
Interaction. Video-Based Studies of Human Sociality.
Social
Interaction. Video-Based Studies of Human Sociality.
2019 VOL. 2, Issue 2
ISBN: 2446-3620
DOI: 10.7146/si.v2i2.116021
Social Interaction
Video-Based Studies of Human Sociality
Co-constructing utterances in face-to-face-interaction:
A multimodal analysis of collaborative completions in spoken Spanish
Dennis Dressel & Alexander Teixeira Kalkhoff
University of Freiburg
Abstract
This article examines collaborative utterances in interaction from a multimodal perspective. Whereas prior research has analyzed co-constructions ex post as the result of local speaker collaboration on the basis of audio data, this study shifts the focus to co-constructing as a highly coordinated, embodied practice. By examining video data of Spanish interactions, this research aims to show how speakers systematically deploy a variety of linguistic and bodily resources that serve as points of joint orientation throughout the process of co-constructing utterances.
Keywords:
co-construction, collaborative utterances, multimodal analysis, Interactional
Linguistics, Conversation Analysis.
1. Introduction
‘Finishing each other’s sentences’ is not only a common idiomatic expression and recurrent trope in literature and film, it is in fact a frequent phenomenon in everyday interaction. In the past, occurrences of collaborative utterances have sparked interest in various research fields, including Sociology, Psychology, Cognitive, and Interactional Linguistics, oftentimes under the premise that two people speaking together must be a demonstration of how close they are.
When looked at ex post, collaboratively produced linguistic units in which a second speaker completes a first speaker’s syntagma, seem to be an inherently syntactic phenomenon. We will argue, however, that in order to successfully co-construct a well-formed syntactic unit, speakers exploit a whole set of linguistic and bodily resources, e.g. syntax, semantics, pragmatics, prosody, gaze, facial expressions, gesture, and posture, that are crucial to the smooth coordination of their speech. With this in mind, we will develop the idea of co-constructing as a joint action, which results in co-constructions as interactionally achieved products.
This conversation-analytic paper investigates collaborative completions in collaborative storytellings in a corpus of video-recorded Spanish interactions. In order to examine instances of local syntactic collaboration between speakers from a multimodal perspective, we analyze the sequential embedding and structure of the unfolding syntactic project. Through detailed multimodal analysis, we aim to contribute a theoretical and analytical point about the affordances of various communicative resources in the context of collaborative utterances.
2. Prior research
Building on Sacks’ early observations on collaborative utterances (1992), the phenomenon of syntactic collaboration in interaction has subsequently been discussed in the fields of Conversation Analysis (Lerner, 1987, 1991, 1996, 2002, 2004a,b; Ono & Thompson, 1995, 1996; Günthner, 2012, 2013; Gülich et al., 2015), Interactional Linguistics (Szczepek Reed, 2000a,b; Auer, 2014; Oloff, 2014; Brenning, 2015), and Dialogic Syntax (Zima, 2013; Du Bois, 2014).
Collaboratively produced linguistic units have been analyzed and conceptualized within different methodological frameworks, predominantly on the basis of English language data. Whereas Sacks (1992) considers the main aspect of collaborative utterances to be that of social coherence and shared knowledge, Lerner (1991, 1996) provides a linguistic framework for the analysis of syntactic collaborations in interaction with his discussion of discussing Compound TCU formats. These two-fold structures link collaborative utterances to prior research on turn organization and provide insight into how speakers use complex syntactic formats (e.g. biclausal constructions, lists, and reported speech) to coordinate their speech. In this context, Lerner describes the interplay between potentially incomplete syntactic structures and their interactional potential: “Any action that foreshows a recognizable completion furnishes an action space” (1991: 453). In our analysis, we will take up the concept of action spaces by showing that they are not only a result of syntactic projection, but locally constituted by the speakers’ gazes and their attention to bodily resources.
Drawing on Construction Grammar, Ono and Thompson (1995, 1996) provide further empirical insights into the syntactic nature of co-constructions by demonstrating how speakers jointly orient themselves towards projectable completion points. By distinguishing collaborative completions from expansions, they view the notions of syntactic (in)completeness and projectability as central features of co-constructions. Szczepek Reed’s research (2000a,b) on the prosodic design of co-constructions investigates the close interplay between syntactic and intonational resources, insisting on a context-sensitive conceptualization of co-constructions as emergent structures.
Prior studies share two common characteristics: firstly, they have mainly analyzed co-constructions ex post as well-formed syntagmata. Secondly, the analyses have been conducted almost exclusively on (English) audio data. Recent studies (cf. Oloff, 2014; Brenning, 2015) have hinted at the importance of visual cues that speakers use to monitor and coordinate their speech in moments of syntactic collaboration. However, no linguistic study thus far has been dedicated to the multimodal organization of syntactic co-constructions in collaborative storytellings.
With co-constructions, especially completions, being local (i.e. micro-structural) phenomena, we also need to consider their sequential embedding in the interaction. This means that we will analyze the preparation, accomplishment, and ratification of local syntactic co-constructions by closely observing the moment at which speakers deploy certain multimodal resources. We focus on collaborative completions, where a second speaker completes a first speaker’s syntactic project. This type of co-construction constitutes moments of maximal interpersonal synchronization, providing evidence for projection as a basic principle of dialogical processing (cf. Auer, 2014). Following the idea of projections at any level (Auer & Pfänder, 2011), we are interested in how speakers use and coordinate various linguistic and bodily resources, i.e. modalities, in order to jointly form utterances in real time.
3. Data and methodology
The Freiburg Sofa Talks (FST) Corpus comprises more than 200 video recordings ranging from 10 to 50 minutes in duration. The corpus encompasses German, Italian, Spanish, French, and Portuguese data, both from European and non-European countries and varieties. It contains 60 Spanish recordings, amounting to a total of 17.5 hours. In each video, two speakers, who know each other well, jointly tell things they have experienced together. Since they recall shared experiences, both speakers have similar epistemic authority (Lerner, 1992). They tell their stories to a third person, who they also both know well. This interlocutor is mostly an unknowing recipient of the collaborative storytelling. Even if the addressee does not actively intervene in the interaction, they must be considered as an integral part of the interaction, since the two speakers design their story for the recipient.
Collaborative storytelling constitutes a context that promotes the object of investigation, a perspicuous setting for our analytic interests. Moreover, the speakers organize their turns without any external interference and choose the topics of their storytelling themselves. This means that all co-constructions in our collection occur naturally without being experimentally produced. Rather, co-constructing appears to be a frequent and situated practice in collaborative storytelling, allowing speakers to jointly reconstruct shared experiences (Gülich et al., 2015). Another important feature of our data consists of its performative nature: the participants often (co-)animate parts of their stories, allowing recipients to experience them in an immersive way. Therefore, we are interested in co-constructing both as an embodied practice in interaction, as well as a means of displaying and negotiating togetherness in the context of collaborative storytelling.
We analyze three examples of collaborative completions drawn from a collection of 90 instances. In order to access the different levels of projection and joint orientation, we have developed an analytical framework that guides our analyses along five dimensions. (1) Syntax: How strongly do the morpho-syntactic features of the first speaker’s utterance project the completion? (2) Semantics: How strongly and on what semantic level does the first speaker’s utterance project the second speaker’s completion? (3) Prosody: Does the first speaker’s prosody imply hesitation and/or project continuation? (4) Pragmatics: Does the co-construction correspond to a recognizable sequential format for both speakers? (5) Body: How do speakers deploy and coordinate bodily resources such as hand gestures, gaze, facial expressions and posture?
By examining these different levels of projection, we aim to gain a deeper understanding of the speakers’ synchronization, based on their joint orientation towards different projective resources. The examples have been transcribed according to the GAT 2 conventions (Selting et al., 2009; Ehmer et al., submitted). The #-symbol embeds screenshots in the transcripts at the exact moment of their occurrence.
4. Analyses
We have chosen the following three examples in order to investigate the roles different resources play in co-constructing utterances. We will argue that in each example, an action space for collaborative completion is constituted by a complex layering of semanto-syntactic projection and situated bodily resources. In our first example, our analysis reveals how even structurally ‘simple’ co-constructions, such as strongly projected last item completions (Sacks, 1992; Lerner, 1996; Auer, 2014), rely on both speakers’ attention to situated bodily resources. In our second example, the more complex Compound TCU format of an emergent list (Lerner, 1991, 1994; Selting, 2004, 2007; Dankel & Satti, 2019) serves both speakers with a clear structural template for the utterance-in-progress. The fact that it becomes a collaborative list, again, requires both speakers’ multimodal coordination. In our third example, a syntactically complete TCU is recompleted by the second speaker. This raises the question: what opens the action space here? We will pursue the answer to this question by analyzing both speakers’ attention to each other’s bodies at a crucial moment in the storytelling.
4.1 LAST ITEM COMPLETION
Example 1: ‘Santiago’
In this example, Lucia (LUC) and her boyfriend Pablo (PAB) discuss how they got to know each other.


Lucia, the main speaker at the beginning of this sequence, yields the turn to Pablo after en dosmilOcho (03), indicated by the TCU-final falling intonation, the possible syntactic completeness of her utterance, and the long pause in (06). Pablo has monitored his interlocutor throughout her talk, nodding during the turn-internal pauses in (01, 02) and the turn-closing pause in (03). He takes the turn in (04), expanding Lucia’s turn with the TCU-initial adverb entonces. His use of the personal pronoun ella suggests that he is not talking directly to Lucia about her but to a third party. In (05), Pablo retracts to the verbal slot conocÍa: with a creaky voice quality as well as the TCU-final lengthening a:_mm:, which indicates hesitation and trouble finishing his utterance. Lucia, alert, moves her head and gaze towards Pablo on conocÍa (05), providing the syntactic and semantically projected element sanTIAgo; (06). Her last item completion closes the prior TCU’s prosodic contour, carrying a focus accent and final falling intonation. At the moment of this collaborative completion, Pablo directs his gaze to Lucia, catching her eye at the exact instant the focus accent is produced. In (07), Pablo ratifies Lucia’s completion by repeating it verbatim: sanTIA:go:, dissolving the mutual gaze. According to Oloff (2014), this is the strongest way of ratifying a second speaker’s contribution in co-constructed utterances. Pablo confirms the completion’s semantic content as well as its morpho-syntactic form, while approving of Lucia locally taking the turn.
Let us now have a closer look at how projection operates in this example in order to facilitate the speakers’ online processing of language. Syntactically, Pablo’s conoCÍA (04) and conocÍa: (.) a:_mm:- (05) project a noun phrase. Therefore, Pablo’s TCU in (05) constitutes an open syntactic project, whose structural incompleteness provides for a closure.
The semantics of the verb conocer project a field of possible mental associations, including locations, proper names, and objects. In this case, both speakers have epistemic access to the story. The sequential context of Lucia studying in CHIle (01-03) projects the name of the place where she used to live and study. The realization of sanTIAgo; (06) is thus situated in the intersection of the general verb semantics of conocer and the semantic salience of the sequence. No other location would be appropriate here: based on the speakers’ locally activated shared knowledge, the semantic projection of Santiago is strong.
Prosodically, Pablo’s creaky voice quality as well as the lengthening on conocÍa: (.) a:_mm:- (09) indicate hesitation. His voice quality changes as he initiates self-repair, making the change in prosody particularly relevant for the production of the utterance in progress. This claim is supported by the observation that Lucia turns her gaze to Pablo at the very moment of the repair initiation. The lack of both a focus accent and a significant TCU-final intonation by the end of line (05) suggests prosodic incompleteness and project continuation.
Pragmatically, this sequence is organized as a word search (Sacks, 1992; Goodwin & Goodwin, 1986; Lerner, 1996; Szczepek Reed, 2000b), where a second speaker comes in to help the first speaker complete their TCU. Lucia recognizes Pablo’s trouble in completing his utterance, and provides the missing item. Pablo, on the other hand, recognizes and ratifies Lucia’s action, integrating her completion into his turn. Therefore, both speakers orient towards an implicit, yet mutually intelligible, format in order to solve a local communicative problem. As a closer multimodal analysis shows, Pablo’s trouble in completing his TCU is not solely a cognitive process, but a “visible activity that others can not only recognize but can indeed participate in” (Goodwin & Goodwin, 1986: 52).

Bodily, this sequence is highly coordinated, with gaze being the most salient resource. Lucia moves her head and directs her gaze towards Pablo on conocÍa (09, Fig. I & II), physically ready to complete after swallowing her sip of mate (cf. Hoey, 2018). She closely monitors Pablo (09), who, with a “thinking face” (ibidem) moves his head and gaze towards Lucia. It is at this moment that Lucia initiates the completion (Fig. III). As part of the multimodal turn-taking-machinery (Schmitt, 2005; Auer 2018), first speaker Pablo’s gaze here operates as an organizational tool, facilitating second speaker Lucia’s intervention. Their eyes meet on the focus accent of sanTIAgo; (10, Fig. III) and the mutual gaze is dissolved as Pablo continues to speak (Fig. V). Both speakers use gaze to locally coordinate turn-taking, allowing for smooth transitions without overlap or pause (cf. Goodwin, 1981; Stivers & Rossano, 2010; Rossano, 2013).
4.2 LIST ITEM COMPLETION
Example 2: ‘presentismo’[1]
In the following extract, two Argentinian friends, Marco (MAR) and Alberto (ALB), are talking about student demonstrations in their home country.

Marco, the main speaker, starts the list by providing the projection component and the first list item: nUnca se reclama por (.) PRÁcticas- (01). He produces PRÁcticas with a strong focus accent and performs a strong lateral head movement to his right side at the same time. As he swings back towards Alberto, he produces the beginning of the second list item o por: °hh (02), with the lengthening and the inbreath projecting continuation. He briefly gazes towards Alberto, who, in response, raises his head and performs an opening gesture with both hands before uttering presenTISmo (03). This one-word utterance smoothly fits the open syntactic structure while providing the focus accent of this collaborative list item. Marco, who was holding his breath during Alberto’s contribution, continues with the next list item (04). He does not overtly ratify or reject his co-teller’s contribution. By continuing with the next list item (04), Marco integrates Alberto’s contribution into his own utterance while preserving the rhythmicity of the list (cf. Schladebeck, 2015; Dankel & Satti, 2019).
Syntactically, the matrix clause (01) and the preposition por: (02) project a noun phrase. Alberto provides a possible completion in concordance with the latent syntactic slot. He does this without retracting to earlier structural slots of Pedro’s utterance but merely fills in the gap, thus creating one single, collaborative syntactic unit. The syntactic pattern established in (01), i.e. [por + noun], is reiterated multiple times, creating a structural parallelism between the TCUs (01) to (05).
Semantically, Marco’s prior speech significantly constrains the options. The overall topic of student protests in Argentina as well as his matrix clause (01) invoke the semantic frame. Moreover, Alberto’s completion relies on the speakers’ shared cultural knowledge as shown by the term presenTISmo (03), which requires cultural membership and local knowledge.
The prosodic design of this co-construction adds to the smoothness and coherence of the two speakers’ utterances. Alberto’s one-word completion presenTISmo (03) has a strong focus accent, indicating that he completes Marco’s TCU. Pedro’s TCU-final PRÁCticas (01) and talLEres (04) have a very similar intonation, adding a certain rhythmicity to these three TCUs. As Lerner (1992) and Selting (2004, 2007) show, lists-in-progress are already recognizable as lists already prior to their completion. Rather than their syntactic structure, it is their prosodic design that makes it easy for the participants to identify and process a list in real time, making lists ideal moments for collaboration (Jefferson, 1990: 82). The highly sedimented list intonation adds a strong pragmatic potential to this format, helping speakers to know when and how to contribute. By marking his TCU in (01) as a preliminary component of a Compound TCU format (Lerner, 1991, 1996), Pedro provides his partner with syntactic, semantic, prosodic and pragmatic information, which subsequently allows both speakers to collaborate on an emerging list. In this sense, the prosodically prompted list format locally provides Alberto with an action space. The syntax of the list item as well as the semantic frame impose restrictions on what Alberto can contribute.
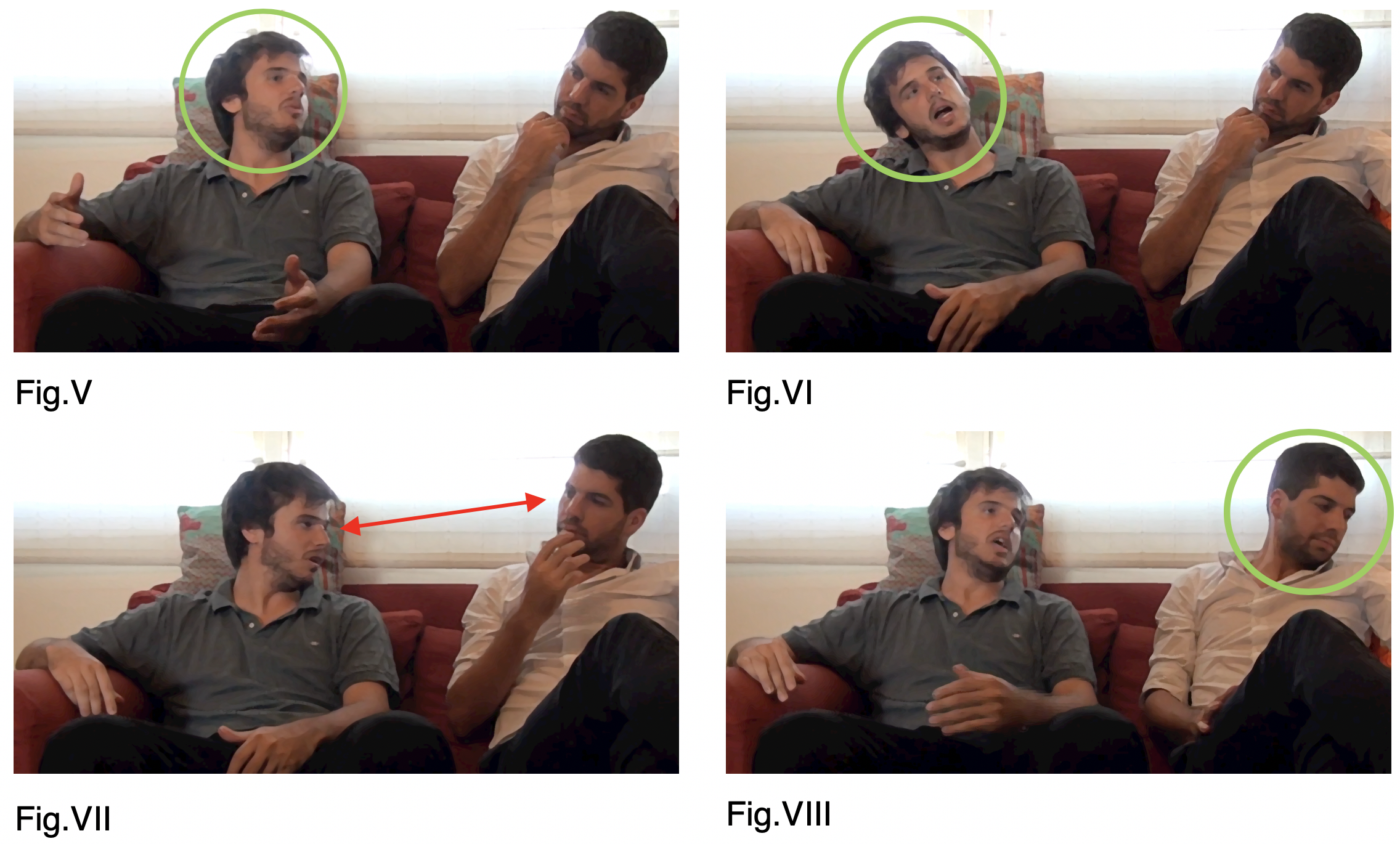
With intonation being a central feature of lists, how do bodily resources contribute to the successful production of a collaborative list in real time? In our example, Pedro accompanies the strong focal accent on PRÁCticas (01) with a marked lateral nod of the head, away from his co-speaker (Fig. V & VI). He then brings his head over to the other side, while briefly directing his gaze to Alberto (Fig. VII), who then awakens from his relaxed posture, performing an opening gesture with his right hand. Pedro’s hesitation and inhalation (02) are accompanied by a vague searching gesture with both hands with his gaze floating through the space before him. These bodily signals allow Alberto to identify Pedro’s pause of speech as a hesitation and possible action space for completion. Alberto completes while directing his gaze towards Pedro, then turns away from him, which signals diminished participation in the activity (Fig. VIII), leaving the role as main speaker to Pedro (cf. Goodwin, 1981; Goodwin & Goodwin, 1987; Rossano 2013).
To sum up, the smooth embedding of Alberto’s speech into Pedro’s sequence is facilitated by both speakers’ joint attention and their knowledge about a very specific syntactic, pragmatic, and prosodic format. Alberto picks up on Pedro’s visual cues, which coincide with the projected syntactic slot and vocal hesitation markers, and promptly help him out without challenging his right to speak. Whereas the emergent list’s syntax and semantics constrained Alberto’s options of what to contribute, Pedro’s body posture, gestures, and gaze allow him to understand when to come in.
4.3 OPPORTUNISTIC (RE)COMPLETION
Example 3: ‘rojo’ (‘red’)
In the third example, Anna (ANN) and José (JOS) share a funny story they experienced together. When playing with a sex toy that had a suction cup, José stuck it to his forehead, leaving him with a red circle which lasted for a week. As the story reaches its climax, José joins in, creating a collaborative punch line.

The punch line unfolds in a multi-part, highly embodied sequence, as both speakers incrementally contribute details to the story. In lines (01) and (02), Anna utters a two-part structure, consisting of the temporal subordinate clause y cuando se lo saCÓ, (01) and the matrix clause teníA_así un CIRculo (02). The latter is then expanded by José’s two-part utterance ROjo /[en la] FRENte (03, 04). Syntactically, the adjective rojo is not projected by Anna’s utterance, but since color words are placed after the noun in Spanish, this very syntactic slot is latently available at the end of her TCU. This semanto-syntactic possibility provides Anna’s co-teller with an action space. The prosodic design of Anna’s matrix clause adds to the collaborative potential, since the rising final intonation projects continuation. In fact, Anna immediately ratifies José’s expansion in line (05), before expanding her matrix clause with the relative clause que duró (.) Una semana (06). Ex post, José’s two-fold structure becomes an internal expansion (cf. Auer 2009: 7) framed by syntactically interdependent structures of the main speaker Anna.

On top of semanto-syntactic latency and intonational cues, it is the speakers’ bodily resources that constitute the action space at the end online (02). Similarly to our previous examples, José (the potential co-speaker) monitors Anna, as her utterance unfolds (Fig. IX). As she produces the TCU-final noun CIRculo (02), this is already projected by her iconic hand gesture (Fig. X). At this point, José visibly anticipates an upcoming action space, as he turns his gaze towards the addressee while bringing his right hand up to his forehead (Fig. X). When looking at the video frame by frame, we see that the action space relies on both speakers’ bodily coordination: Throughout her matrix clause (02), Anna establishes an iconic gesture (Fig. IX-XI) on her forehead, which is the central semantic element of the story’s climax. She briefly pauses after CIRculo (02), while holding this gesture and maintaining a high body tension, with her torso and face directed towards the addressee (Fig. X). By keeping up this static bodily expression, she bridges her co-speaker’s expansion, ready to reprise her role as main speaker. During this moment of bodily stillness, her eyes quickly wander to her co-speaker, who then starts to speak (Fig. XI).
In overlap with the second part of José’s expansion, Anna expands her matrix clause (06), bringing her syntactic project as well as the punch line to an end. At the same time, she releases some of her body tension and dissolves the static gesture, resuming more dynamic co-speech gestures (Fig. XII).
When looking at this sequence as a coordinated interactional achievement, it is remarkable how the two speakers collaborate on both a verbal and bodily level in order to transform a shared memory into an entertaining story. However, José’s own physical experience and epistemic primacy allow him to locally join Anna’s storytelling and assume the role of an active co-teller. José also uses this role to provide additional humorous value to the story: he provides anticipatory laughter (Lerner, 1992: 259) and he locally contributes relevant information by syntactically and semantically expanding Anna’s turn. On a bodily level, he picks up Anna’s gesture, supporting her status as teller. Their joint gaze orientation towards the addressee indicates that the story is designed for the recipient; both speakers visibly make an effort to entertain their audience.
5. Discussion: What do we gain by looking at the body/ies?
For heuristic reasons, we stipulated an analytical framework that takes into account five dimensions on which projection operates in collaborative sequences. Syntactic, semantic, pragmatic, prosodic, and bodily resources serve speakers as orientational points when co-constructing an utterance. The activity of co-constructing relies on the speakers’ attention towards locally activated resources, whose functions in the utterance-in-progress are not determined a priori, but are negotiated by the participants.
In our first example, we analyzed a word search sequence in which the second speaker completes her interlocutor’s utterance by providing the last item of the TCU. These sequences have been described as a syntactic and pragmatic format designed for conditional entry by the co-teller (Lerner, 1996: 261). In our example, the last item is strongly projected by the syntax of the utterance-in-progress and semantics of the sequence. However, we have seen that the word search, as “visible activity” (Goodwin & Goodwin, 1986: 52), relies on the main speaker’s situated bodily resources, in this case his creaky voice and gaze towards his interlocutor. These visual cues are closely monitored by the potential co-teller, who then comes in at the right time. Whereas the bodily resources initiate and facilitate the joint action of co-constructing, the unfolding syntax and semantics serve as a structural template to the speakers’ joint utterance.
In our second example, we showed how the format of an emergent list serves as a structural and rhythmical template to the speakers’ joint utterance. The list format is prompted by its initial list prosody. Structurally and semantically, the projected second list item is highly constrained by the first list item. For the emergent list to become a collaborative list, bodily resources come into play. The second speaker’s entry is facilitated by the first speaker’s gaze towards his interlocutor at a moment when the structural continuation of the TCU is strongly projected.
In our third example, the first speaker’s utterance has reached a possible completion point. Her prosody, however, indicates possible continuation. Moreover, the first speaker’s holding gesture as well as her brief eye gaze towards her co-teller provide the latter with an action space. The co-teller takes advantage of this opportunity and expands the utterance’s latent structure, contributing further details to the story and creating a collaborative punch line.
All three examples show that the unfolding semanto-syntactic structure serves as a template for what it is that the second speaker might say (What do I say?). The active pragmatic format as well as prosody and bodily resources, on the other hand, determine whether the second speaker completes the utterance and, if so, at what moment in the interaction (Should I? What will I do? When will I do it?).
6. Conclusion
When looking at collaborative utterances, it is remarkable that speakers almost always produce syntactically well-formed units: co-constructions. However, syntax is only one of many projective resources that allow speakers to anticipate possible completions. In our analyses of collaborative storytellings, we found that the syntax of the utterance-in-progress imposes major constraints on how the co-teller may or may not complete the main speaker’s TCU. Possible syntactic completions are further limited by the semantics of the latent structure within the ongoing sequence as well as the speakers’ shared knowledge. Therefore, syntax and semantics give shape to co-constructions as the result of a joint action.
The joint action of co-constructing utterances, on the other hand, strongly relies on locally salient bodily resources, such as gaze, facial expressions, posture, gesture, and voice quality. Situated bodily resources have been shown to play a crucial role in initiating and accomplishing co-constructing by serving speakers with mutually intelligible points of orientation in interaction. Therefore, both structurally projected action spaces and emergent co-constructions can be fully understood only by means of multimodal analysis.
7. References
Auer, P. (2009). On-line syntax: Thoughts on the temporality of spoken language. Language Sciences, 31, 1-13.
Auer, P. (2014). The temporality of language in interaction: Projection and latency. In A. Deppermann & S. Günthner (Eds.), Temporality in Interaction (pp. 27-56). Amsterdam, Netherlands: Benjamins.
Auer, P. (2018). Gaze, addressee selection and turn-taking in three-party interaction. In G. Brône & B. Oben (Eds.), Eye-tracking in Interaction (pp. 197-232). Amsterdam, Netherlands: Benjamins.
Auer,
P. & Pfänder, S. (2011). Multiple retractions in spoken French and spoken
German. A contrastive study in oral performance styles. Cahiers de praxématique, 48, 27-84.
Brenning,
J. (2015). Syntaktische Ko-Konstruktionen im gesprochenen Deutsch. Heidelberg,
Germany: Winter. Dankel,
P. & Satti, I. (to appear 2019). Multimodale Listen: Form und Funktion
körperlicher Ressourcen in Aufzählungen in französischen, spanischen und
italienischen Interaktionen. Romanistisches Jahrbuch, 70. Du
Bois, J. (2014). Towards a dialogic syntax. Cognitive Linguistics, 25(3),
359‑410. Ehmer,
O. et al. (submitted). Un sistema para transcribir el habla en la interacción:
GAT 2.Online-Zeitschrift zur verbalen Interaktion.
www.gespraechsforschung-ozs.de. Goodwin,
C. (1981). Conversational Organization: Interaction between speakers and
hearers. New York, United States: Academic Press. Goodwin,
M. H. & Goodwin, C. (1986). Gesture and coparticipation in the activity of
searching for a word. Semiotica,
62(1/2),
51-75. Gülich,
E., Dausendschön-Gay, U. & Krafft, U. (Eds.). (2015). Ko-Konstruktionen
in der Interaktion. Bielefeld, Germany: transcript. Günthner,
S. (2012). ‘Geteilte Syntax’: Kollaborativ erzeugte dass-Konstruktionen. GIDI-Arbeitspapier,
43 (University of Münster, Germany). Günthner,
S. (2013). Ko-Konstruktionen im Gespräch: Zwischen Kollaboration und
Konfrontation. GIDI-Arbeitspapier, 49 (University of Münster,
Germany). Hoey,
E. (2018). Drinking for speaking: The multimodal organization of drinking in
conversation. Social Interaction. Video-Based Studies of Human Sociality 1(1). Jefferson,
G. (1990). List-Construction as a Task and Resource. In G. Psathas (Ed.), Interaction
Competence (pp. 63-92). Washington (D.C), United States: University Press
of America. Lerner,
G. (1987). Collaborative turn sequences: Sequence construction and social
action. (Doctoral dissertation). University of California Irvine, CA. Lerner,
G. (1991). On the syntax of sentences-in-progress. Language in Society, 20,
441-458. Lerner,
G. (1992). Assisted Storytelling: Deploying Shared Knowledge as a Practical
Matter. Qualitative Sociology, 15(3), 441-458. Lerner,
G. (1994). Responsive List Construction: A Conversational Resource for
Accomplishing Multifaceted Social Action. Journal of Language and Social
Psychology, 13(1), 20-33. Lerner,
G. (1996). On
the ‘semi-permeable’ character of grammatical units in conversation:
Conditional entry into the turn space of another speaker. In E. Ochs, E. A.
Schegloff, & S. A. Thompson (Eds.), Interaction and Grammar (pp.
238-276). Cambridge, United Kingdom: Cambridge University Press. Lerner,
G. (2002). Turn-sharing: The choral co-production of Talk-in-Interaction. In C.
Ford (Ed.), The Language of turn and sequence (pp. 225-256). Oxford,
United Kingdom: Oxford University Press. Lerner,
G. (2004a). Collaborative turn sequences. In G. Lerner (Ed.), Conversation
Analysis: Studies from the first generation (pp. 225-256). Amsterdam,
Netherlands: Benjamins. Lerner,
G. (2004b). On the place of linguistic resources in the organization of
Talk-in-Interaction: Grammar as action in prompting a speaker to elaborate. Research
on Language and Social Interaction, 37, 151-184. Oloff,
F. (2014). L’évaluation des complétions collaboratives: Analyse séquentielle
et multimodale de tours de parole co-construits. Retrieved from
https://www.zora.uzh.ch/id/eprint/104544/1/shsconf_cmlf14_01130.pdf Ono,
T. & Thompson, S. (1995). What can conversation tell us about syntax? In P.
Davis, (Ed.), Alternative Linguistics: Descriptive and theoretical modes (pp.
213-271). Amsterdam, Netherlands: Benjamins. Ono,
T. & Thompson, S. (1996). Interaction and Syntax in the Structure of
Conversational Discourse. In E. Hovy & J. Heritage (Eds.), Structures
of Social Action: Studies in Conversation Analysis (pp. 28-52). Cambridge,
United Kingdom: Cambridge University Press. Rossano,
F. (2013). Gaze in Conversation. In J. Sidnell & T. Stivers (Eds.), The
Handbook of Conversation Analysis (pp. 308-329). Malden, United States:
Wiley-Blackwell. Sacks,
H. (1992). Lectures on conversation. Ed. by G. Jefferson. Oxford, United
Kingdom: Blackwell. Schladebeck,
A. (2015). Rhythm as a resource to generate prosodic coherence in lists. In R.
Vogel & R. van de Vijver (Eds.), Rhythm in Cognition and Grammar. A
Germanic Perspective (pp. 277-310). Berlin, Germany: De Gruyter Mouton. Schmitt,
R. (2005). Zur
multimodalen Struktur von turn-taking. Gesprächsforschung –
Online-Zeitschrift zur verbalen Interaktion, 6, 17-61. Selting,
M. (2004). Listen: Sequenzielle und prosodische Struktur einer kommunikativen
Praktik – eine Untersuchung im Rahmen der Interaktionalen Linguistik. Zeitschrift
für Sprachwissenschaft, 23, 1-46. Selting,
M. (2007). Lists as embedded structures and the prosody of list construction as
an interactional resource. Journal of Pragmatics, 39(3), 483-526. Selting, M. et al. (2009). Gesprächsanalytisches
Transkriptionssytem 2 (GAT2). Gesprächsforschung: Online-Zeitschrift zur
verbalen Interaktion, 10, 353-402. Stivers, T. & Rossano, F. (2010). Mobilizing Response. Research
on Language & Social Interaction, 43(1), 3-31. Szczepek
Reed, B. (2000a). Formal aspects of collaborative productions in English
conversation. Konstanz,
Germany: Fachgruppe Sprachwissenschaft, Universität Konstanz. Szczepek
Reed, B. (2000b). Functional aspects of collaborative
productions in English conversations. Konstanz, Germany:
Fachgruppe Sprachwissenschaft, Universität Konstanz. Zima,
E. (2013). Cognitive Grammar and Dialogic Syntax. Review of Cognitive
Linguistics, 11(1), 36-72.